Chapter 9 Week 9
9.1 Learning outcomes
This week, we consider another important factor that is present in our data that we don’t always talk about, and that is the importance of time. The importance of place in criminology and crime analysis is widely discussed. We know certain areas can be crime hotspots, and we know that whether you come from a well-off or deprived area, you have different access to resources, and therefore, your outcomes in terms of involvement with the criminal justice system also differ. However, time is just as important as place. We often hear that crime is “going up” or “going down” over time. It is very important that, as a well-rounded criminologist, you are able to talk about these concepts with appropriate knowledge and understanding.
When violence increases between March and August, is that because we are seeing an increase in crime and offending? Or is it possible that the time of year has something to do with this? How much must crime increase and over how long of a time in order to be able to confidently say that crime is on the increase? These are important and not always easy questions to answer, and this week, we will begin to think about this.
Here are some terms that we will cover today:
- Crime trends
- Temporal crime analysis
- Seasonality
- Time series data analysis
- Moving averages
- Smoothing techniques
- Seasonal decomposition
- Signal vs noise
9.2 Crime and incident trend identification
All crimes occur at a specific date and time. If there are victims or witnesses present or alarms are triggered, we can note this specific time. Unfortunately, this is not always the case. For example, burglary is often discovered only when the homeowner returns from work, which may be hours after it actually happened. This is something to keep in mind when working with temporal data.
Temporal crime analysis looks at trends in crime or incidents. A crime or incident trend is a broad direction or pattern that crime and/or incidents are following.
Three types of trends can be identified:
- Overall trend – highlights if the problem is getting worse, better or staying the same over a period of time
- Seasonal, monthly, weekly or daily cycles of offences – identifies whether there are any patterns in crimes associated with certain time periods, for example, burglaries increasing in the winter, dying down in the summer, and increasing again the next winter.
- Random fluctuations are caused by a large number of minor influences or a one-off event and can include displacement of crime from neighbouring areas due to partnership activity or crime initiatives.
This week, we will be looking at crime data from the USA. As you saw, the data from police.uk is aggregated by months. We do not know when the offences happened, only the month, but nothing more granular than that. American police data, on the other hand, is much more granular.
Specifically, we will be looking at crimes from Dallas, Texas. You can see more about these data and find the download link to the data dictionary here: https://www.dallasopendata.com/Public-Safety/Police-Bulk-Data/ftja-9jxd. However, for this lab, you can download a subset of Dallas crime data from Blackboard. Go to Learning Materials > Module 9 > Data for Labs and Homework, and the file is dallas_burg_correct.xlsx. Download this and open it up in Excel.
When you open the Excel spreadsheet, you will see that there is a column for date called Date.of.Occurrence. The date is in the format dd/mm/yyyy. The first date on there, you can see, is 31/12/14.
But what if we asked you the question: which year had the most residential burglaries? Or what if we want to know if residential burglaries happen more on the weekday when people are at work, or at the weekends, maybe when people are away for a holiday? You have the date, so you should be able to answer these questions, right?
Well, you need to have the right variables to answer these questions. To know what year saw the most residential burglaries, you need to have a variable for the year. To know what day of the week has the most burglaries, you need to have a variable for the day of the week. How can we extract these variables from your date column? Luckily, Excel can help us do this.
9.2.1 Activity 9.1: Formatting your dates appropriately
In this activity, we will learn how to take a date and extract the elements required for our analyses. First, you want to make sure that your date column is, in fact, a date and is interpreted by Excel as well. To be sure, you can right-click on the column and select “Format cells…”:
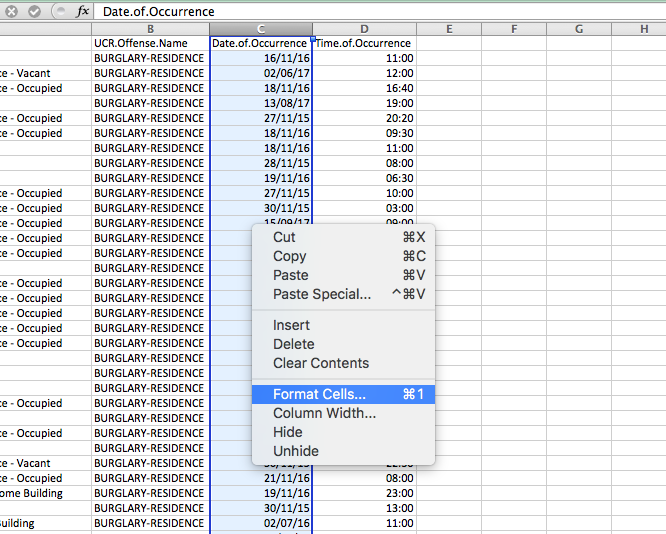
Under the “Category” sidebar, select “Date”, and pick a format that matches your date layout (for example, in this case, it’s date-month-year).
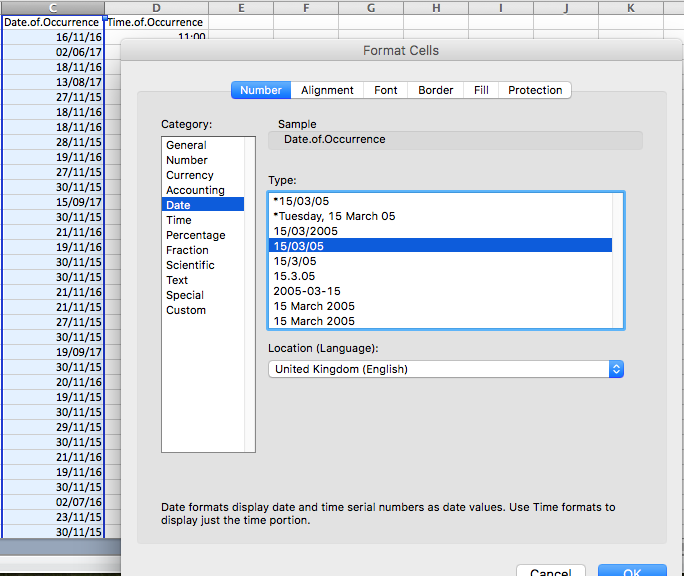
This way, you ensure that Excel knows your date column is a date. It also ensures it is in the appropriate format. In some countries, dates are formatted differently. For example, in the United States, it is customary to format the date as month/day/year. In the UK, this is formatted as day/month/year.
9.2.2 Activity 9.2: Extracting temporal variables from dates
Now, let’s start by answering our first question: which year had the most burglaries? To answer this, we first need a variable for the year. Let’s extract this from the date column. We can do this with the =year() function. Inside the brackets, you just have to put the date from which to extract the year.
First, let’s create a new column called “Year”, like so:
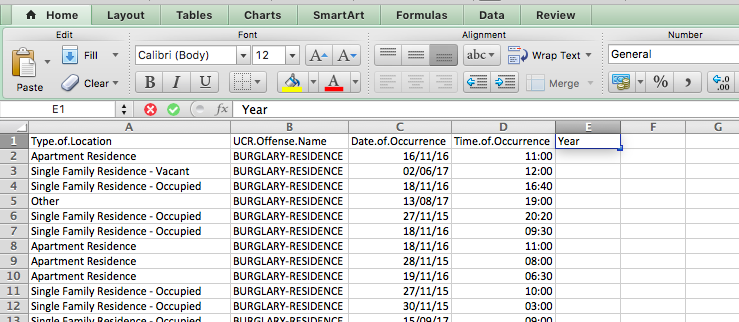
Then, for the first cell, enter the formula =year(), and inside the brackets, put the date value for the first row, in this case, cell C2:
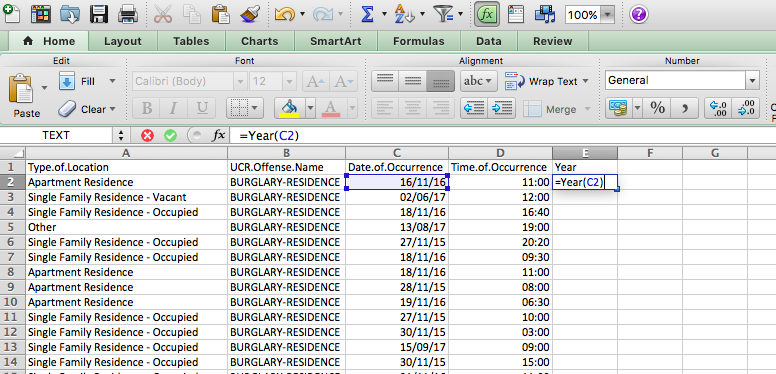
You will see the cell be populated with the value for the year, in this case, 2016. Copy the formatting down to populate the whole “Year” column:
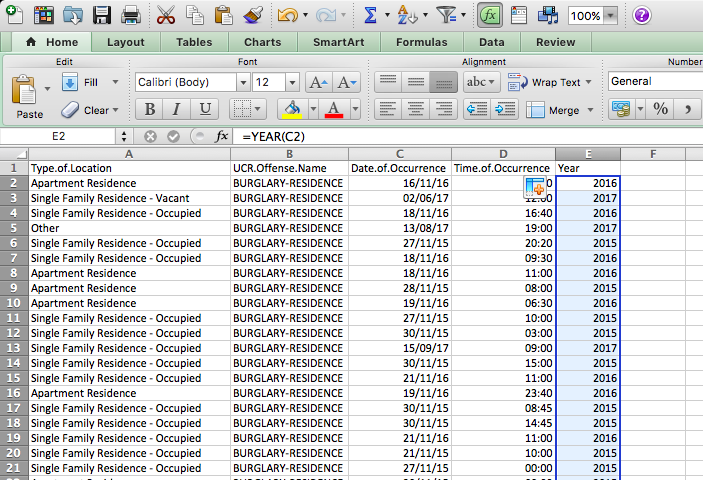
Ta-daa! You now have a column of years! How do you find out which year has the most burglaries? We’ve now created a variable year that you can use to apply what you learned from the previous weeks; specifically, since we are analysing one variable, we will apply…. univariate analysis. You can create a frequency table for the ‘Year’ column you selected using a pivot table
Try to do this now with no further guidance. If you need some help, have a look at your notes from the univariate analysis lab in week 2.
So… which year had the most residential burglaries?

To answer this question, hopefully, you built a pivot table with the year variable, and your table should look like this:
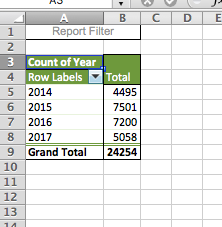
Hopefully, you got a similar result. If not, now is the time to discuss or ask for help in your groups. You can now see that the year with the highest number of residential burglaries in Dallas was 2015. You should note that since 2017 was not yet over at the time of data collection, you have incomplete data for this year, so you’re not comparing like for like. Always think about how to interpret your findings, and keep in mind any possible limitations and issues associated with your data.
9.2.3 Activity 9.3: Extract the day of the week from the date column
Now let’s go back to our 2nd question - do residential burglaries happen more on weekdays, when people are at work (pre-COVID times anyway…) or at the weekends, maybe when people are away for a holiday?
To answer this question, we need another variable to represent the day of the week. First, create a new column; call it Day.of.Week:
Then, you can go ahead and fill this column with the day of the week. To do this, you can use the =text() function. You have to pass two parameters to this function. The first is the value of the date column again, as was the case with the year function, and the second is the format that you want the text to take.
If you ever forget this, you can use the little popup help that Excel uses to remind you:
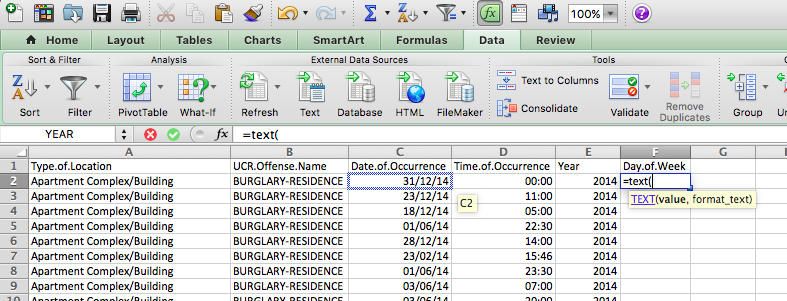
The value parameter, just like with the year function, is the cell in the Date.of.Occurrence column. In the case of our first row here, it’s C2. The second value is the format parameter. Depending on what you enter here, a different value will be returned by the text() function. Here is a list of values and their results:
- d: 9
- dd: 09
- ddd: Mon
- dddd: Monday
- m: 1
- mm: 01
- mmm: Jan
- mmmm: January
- mmmmm: J
- yy: 12
- yyyy: 2012
- mm/dd/yyyy: 01/09/2012
- m/d/y: 1/9/12
- ddd, mmm d: Mon, Jan 9
- mm/dd/yyyy h:mm AM/PM: 01/09/2012 5:15 PM
- dd/mm/yyyy hh:mm:ss: 09/01/2012 17:15:00
Let’s use the “dddd” option here to extract the full name of each weekday. To do this, your formula should be:
=text(C2, "dddd")
Like so:
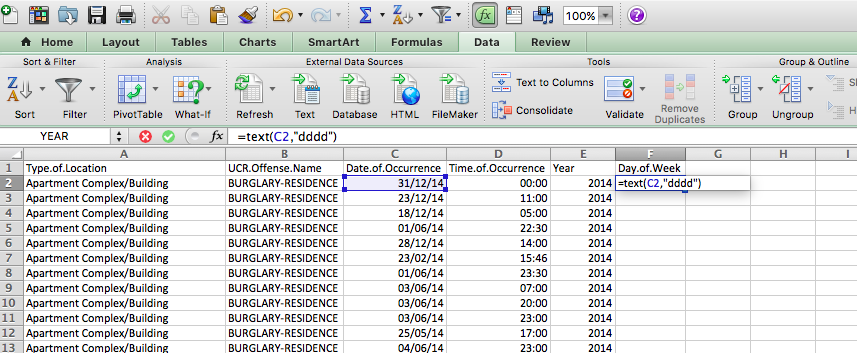
Now copy this for each row, and you will now find out the day of the week that each one of these burglaries falls on:
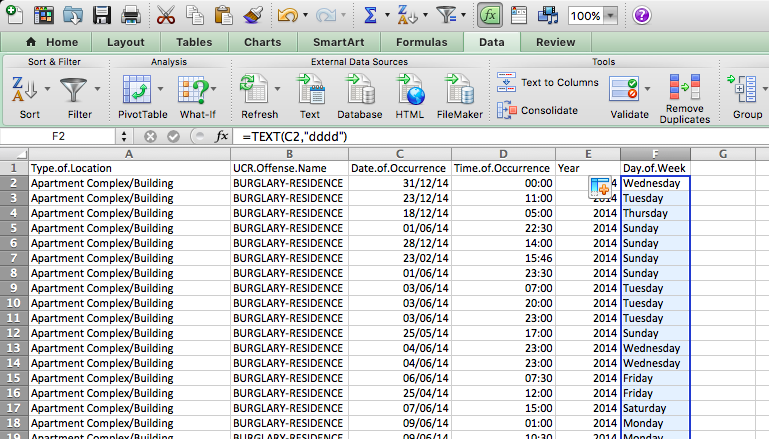
NOTE: If this is not working for you, it is possible that your laptop/Excel/operating system is set to a different language. For example, if you have a laptop that is set to French, instead of “dddd” (which means daydaydayday to Excel), it will be looking for “jjjj” (journéejournéejournéejournée). If you have a laptop set to a language other than English, think about how you say the date you’re trying to extract (day or month or year, etc.).
Now, we want to compare burglary on weekdays to the weekend. Can you make a pivot table that answers our question about weekends and weekdays? Well, not quite just yet. You would need a column for weekday/weekend. How can we do this?
9.2.4 Activity 9.4: Recoding days of the week
Well, think back to when we did re-coding in week 4. Remember the VLOOKUP() function? Remember the VLOOKUP() function takes four parameters. You have to tell it the lookup_value - the value to search for. You then have to tell it the table_array - which is your lookup table, with two columns of data. The VLOOKUP function always searches for the lookup value in the first column of table_array. Your table_array may contain various values such as text, dates, numbers, or logical values. You then have to tell it the col_index_num - the column number in table_array from which the value in the corresponding row should be returned. Finally, you still have to specify the range_lookup. This determines whether you are looking for an exact match (when you set it to FALSE) or an approximate match (when you set it to TRUE or omit it).
The first thing you have to create is your lookup table. For each value of day of the week, you should assign a value of Weekday or Weekend. Something like this:
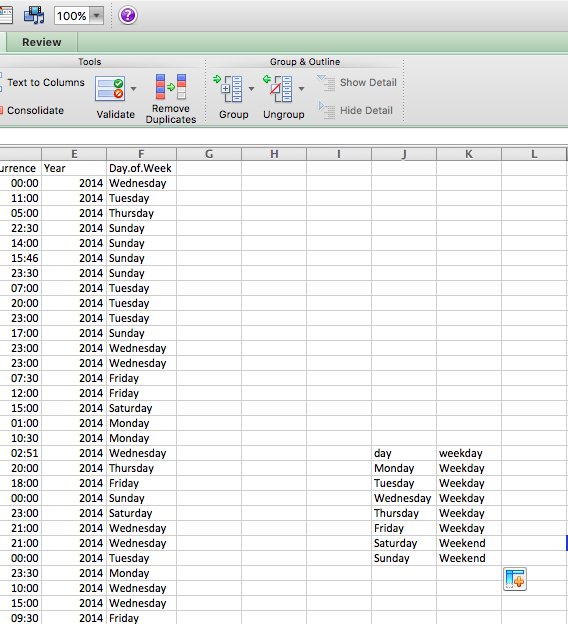
Note: Remember what you learned with lookup tables in Week 4, and refer back to the notes from then if necessary. One common issue we experienced is that sometimes, Excel would fail to match something like ” Wednesday” or “Wednesday” or “wednesday” because the value in the lookup table actually said “Wednesday”. The easiest way to make sure no such errors pop up to drive you mad is to copy and paste each day from the original data set into the lookup table. If you are doing this, make sure that you are pasting values (not the formula).
Now, let’s try to apply the formula.
- lookup_value is the day of the week
- table_array is this table we just created
- col_index_num is the column which contains the values to translate into
- range_lookup set this to FALSE, so we match on exact matched only
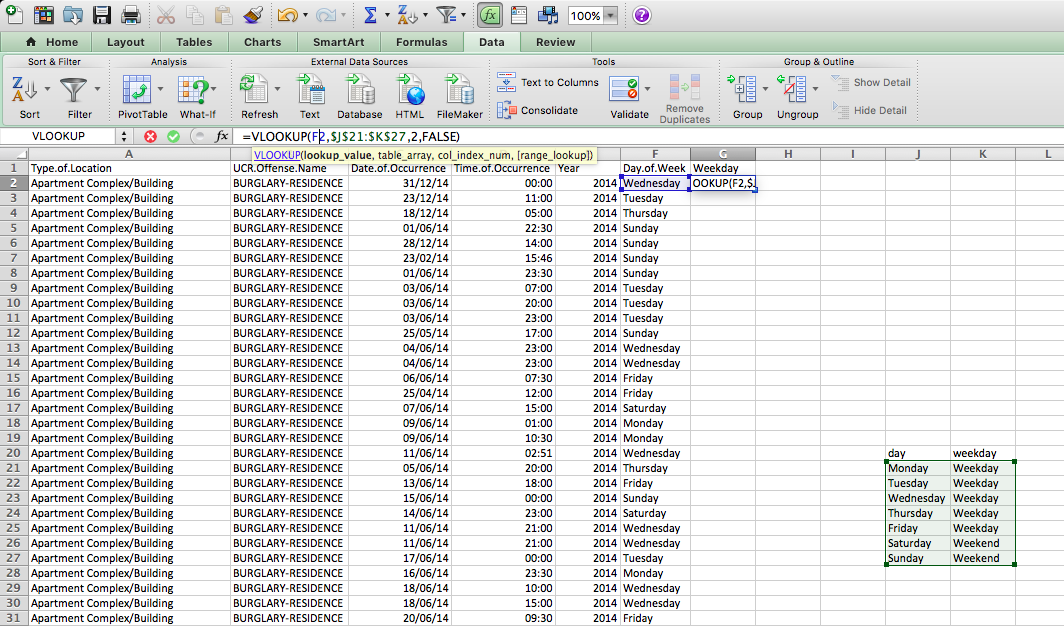
Make sure to add the dollar signs ($) to ensure that you can copy the formatting!
Now, finally, you have a variable that tells you whether each burglary took place on a weekday or a weekend:
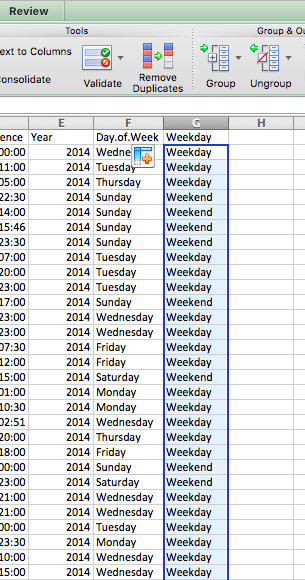
9.2.5 Activity 9.5 patterns in residential burglary
Now, you can use this variable to carry out univariate analysis and create a frequency table to see the number of burglaries on weekdays or weekends. Let’s create this pivot table:
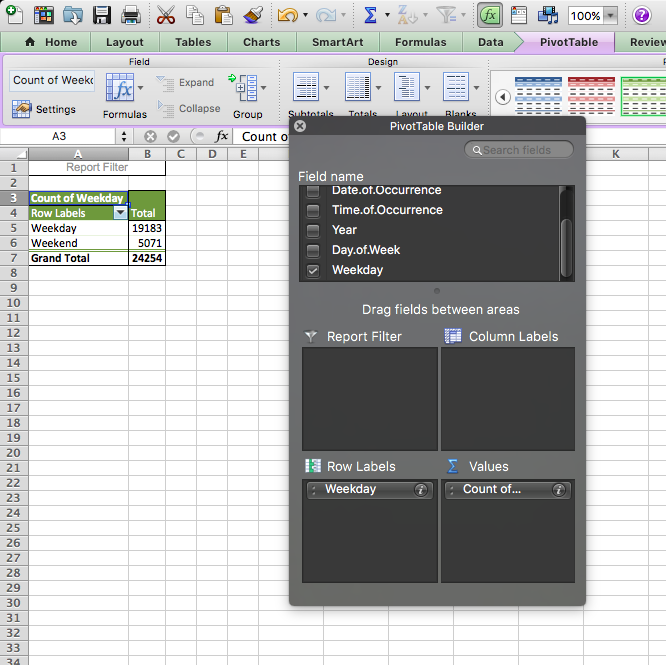
Unsurprisingly, when we look at the number of burglaries in each group, we see there are a lot more burglaries on weekdays than at weekends. Why do you think that is? Take a moment to discuss in small groups, and write your thoughts!

What did you discuss? We are hoping that you mentioned that there were a lot more weekdays than weekend days in our data and in fact, in all weeks. There are 2.5 times as many weekdays than weekends in a week. We know it’s a sad truth; we work a lot more than we get to rest. But another thing that happens because of this is that simply looking at the number of burglaries on weekdays and weekends might not be a very meaningful measure. Remember when we spoke about comparing like for like earlier? Or last week, when we talked about the crime rate (per 100,000 population) versus the number of crimes? Well, again here, we should calculate a rate; to truly be able to compare, we should look at a rate such as the number of burglaries per day for weekdays and the number of burglaries per day for weekend-days.
How do you calculate the rate? Well, you do this simply by dividing the numerator (number of burglaries) by an appropriate denominator. What is the best denominator? Well, it depends on the question you’re looking to answer. Usually, it’s what comes after the per. If we are looking for the number of crimes per population, then we will be dividing by the population. If we are looking at the number of burglaries per household, we will divide by the number of households in an area. In this case, we were talking about the number of burglaries per day to compare between weekends and weekdays. Your denominator will be the number of days for each group.
To get the burglary rate (per day), we simply take our total number of burglaries from our pivot table and divide by the number of days for each. As we know, there are five weekdays (boo) and two weekends (yay). So let’s divide accordingly:
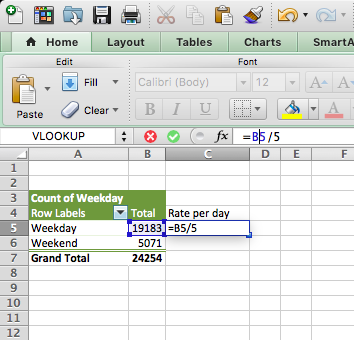
And copy also for the weekends, and voila, we have our answer to the question, are there more burglaries on weekdays or weekends:
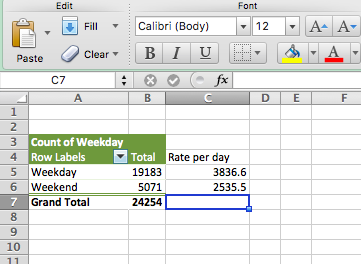
Now you can discuss again why you think this might be. For example, during the week, people are away from their homes for work for the majority of each day, which leaves their homes unprotected. I’ve mentioned the crime triangle before. If the resident is not home, then there is an absence of a capable guardian, and there is an increased risk for a crime (such as burglary) to occur! Write down any other theories/thoughts you might have about this!
There are many things that peak on certain days of the week if you’re interested in some more examples, read this article in the Guardian about the most dangerous days of the week.
9.3 Aggregating to simple intervals
In the above activities, you were able to extract certain types of date categories from the date column. If we want to compare year-on-year increases or decreases, this is one approach. Or if we want to compare the day of the week, the month of the year, and so on. We did this by creating a new variable and then using a pivot table. We could also look at the date as it is, and we could have a look at the number of crimes each day, but often, this can be noisy. Instead, sometimes, we want to aggregate (group) these into simpler time intervals.
First, we’ve not had a look at our time variable yet, so we could start with that.
9.3.1 Activity 9.5: Aggregate by hour
Let’s say we want a bit more granularity. We want to see when within the day these crimes occur. We can see that we have a Time.of.Occurrence variable, which has the exact time. But this is very precise, and aggregating to the minute might not let us see greater patterns. Also, if we aggregate to the minute, we communicate that we really trust the precision of the data on when the crime occurred, which, especially in the case of burglary, might be fishy. Think about it for a moment - if the homeowner is out all day, and the burglar breaks in at 12:30, when will the crime be reported - when it occurred, or when the homeowner returns from work in the evening? Hmm Hmm. In this case, let’s aggregate to the nearest hour.
To do so, first, create a new column for ‘Hour’:
Then, use the =HOUR() function to extract the hour, just like we did to get the year using the =YEAR() function. Except, this time, we are extracting the hour from the “Time.of.Occurrence” variable rather than the “Date.of.Occurrence” variable. Like so:
And finally, copy your formatting to all the rows:
Now you have a column for the hour that the offence was committed in! Have a think about how you are aggregating here though. As you can see, this function simply takes the hour when the incident occurred. So something that happened at 14:01 and 14:59 will both be grouped to 14:00. Is this a problem? Well, it depends on the sort of granularity of analysis that you will be carrying out. Most of the time (particularly with burglary, as mentioned above), we struggle to get an accurate understanding of the time the incident happened. But there may be cases when more precision is needed; in that case, you might want to consider the hours and minutes or think about other ways to aggregate (group) your data.
You could also extract something else, for example, the month and year from the date. To do this, you simply use this, again create a new column, and this time, use a formula that extracts text from the date:
=TEXT(*cell reference*,"mmm-yyyy")
In where it says cell reference, just put in the reference to the column from the date (in this case it’s C) and the cell number (2 for the first row).
=TEXT(C2,"mmm-yyyy")
You can then copy this formula down to the whole data set.
NOTE: Now, there is also a new feature in Excel 2016 that allows you to do automatic grouping by time. You can have a look through this tutorial to show you how you can use this new feature. This will be important in a moment as well when we try to group for specific dates, so do take some time to think about this!
What can we do with all this great temporal data? Well, let’s start by visualising!
9.4 Visualising time
Depending on what you’re visualising, you can use either a linear approach or a cyclical approach. A linear approach makes sense if you’re plotting something against passing time. If you are looking at whether a trend is increasing or decreasing, this is something you would look at over time because it would be moving forward.
On the other hand, many measures of time are cyclical. For example, remember in the very first week, when we spoke about levels of measurement of variables, and we had a variable for time, and mentioned that this was not a numeric variable; instead, it was categorical-ordinal because it loops back around. After the 23rd hour of a day comes the 0 hour of the next! So, representing this on a linear graph may mask some important variations. Let us show you an example:
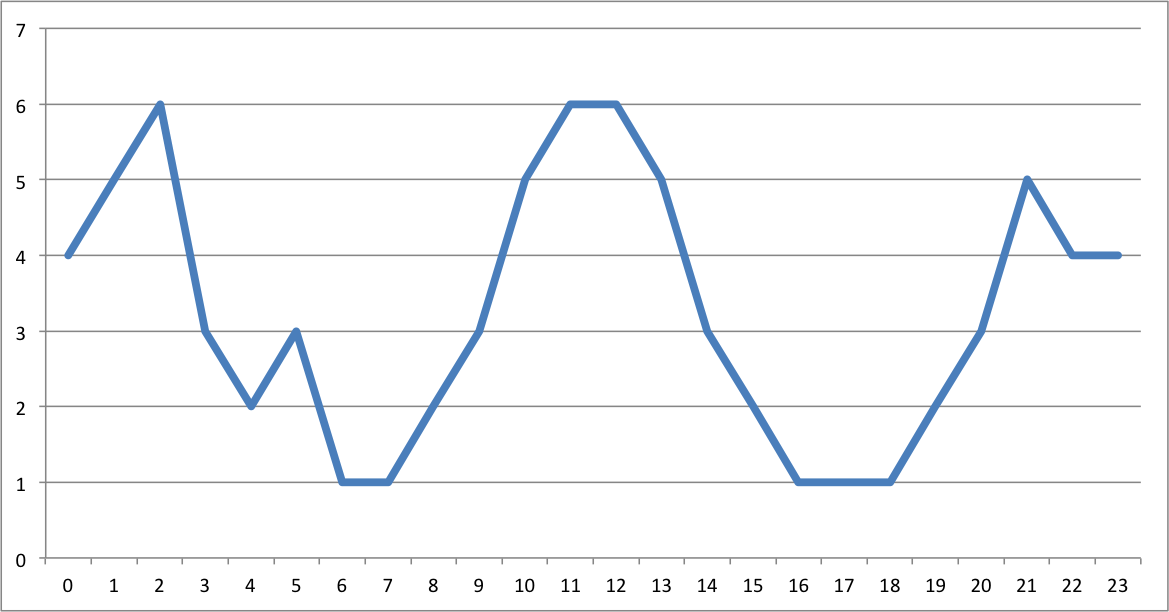
The above is some made-up data of something over the hours of a day. What do the peaks there look like to you? If we were looking at this, we would say we have three peaks. There is a peak in the early hours of the morning, like 1-2 am, then again a peak midday, and again another peak in the evening around 9 pm.
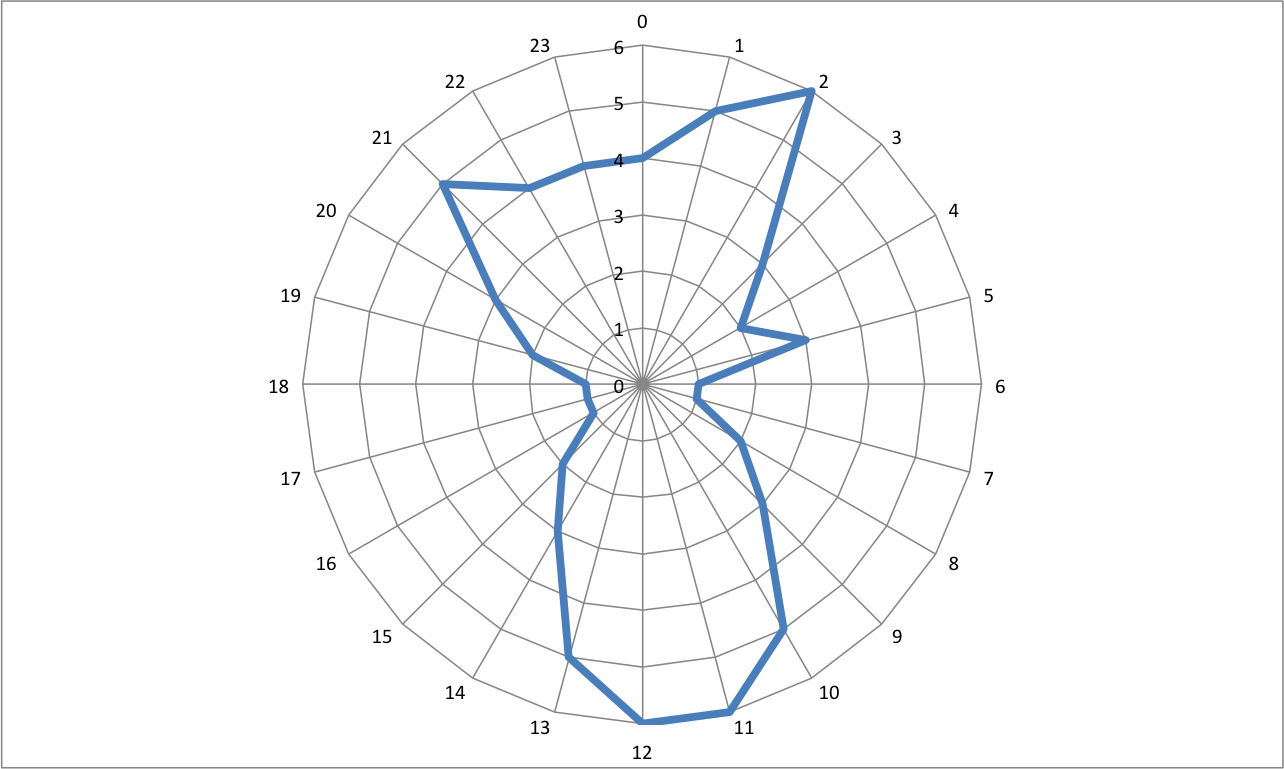
This is the same data but visualised in a cyclical way. In this visualisation, it actually appears that there are two main peaks. The peaks that were previously identified as two separate, possibly independent peaks have now bridged into 1, and we can see that instead, there might be a continuum and an ongoing event from 9 pm to 2 am. It is important to consider the cyclical nature of some of your temporal variables and use the appropriate means to visualise them.
It might be worth having a look at some examples of temporal data being visualised, as well as making our own visualisations of time. Here, we will focus on three approaches: line graphs, radar graphs, and heatmaps.
9.5 Visualising trends: Line graphs
Let’s start with viewing some examples of time visualised using a timeline of continuous time passing:
The world of sports is rich with data, but that data isn’t always presented effectively (or accurately, for that matter). The folks over at FiveThirtyEight do it particularly well, though. In this interactive visualization below, they calculated what’s called an “Elo rating” – a simple measure of strength based on game-by-game results – for every game in the history of the National Football League. That’s over 30,000 ratings in total. Viewers can compare each team’s Elo to see how each team performed across decades of play. See here
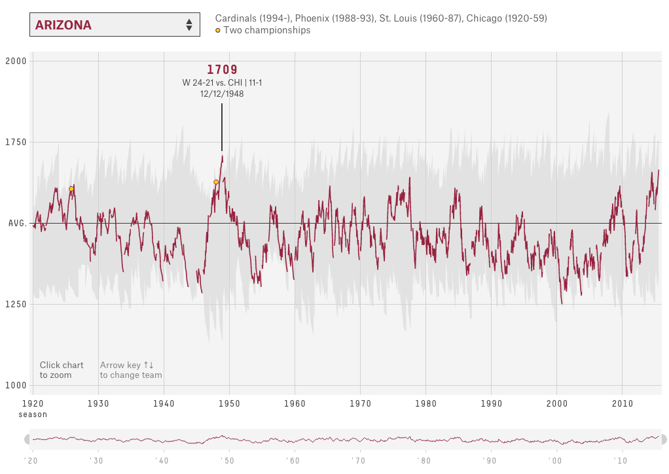
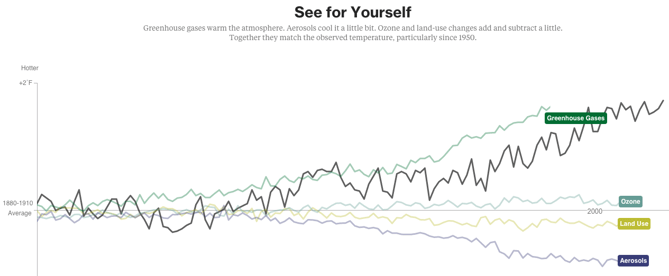
Another example of a continuous timeline is the “What is warming the world” visualisation. Ever heard a version of the advice, “Don’t simply show the data; tell a story with it”? That’s exactly what this visualization from Bloomberg Business does – and it’s the interactive part that makes the story move along from beginning to end.
The point of the visualization is to disprove theories that claim that natural causes explain global warming. The first thing you’ll see is the observed temperature, which has risen from 1880 to the present day. As you scroll down, the visualization takes you through exactly how many different factors contribute to global warming in comparison to what’s been observed, adding a richer layer of storytelling. The conclusion the authors want viewers to draw is made very clear. See here
9.5.1 Activity 9.6: Visualising trends: Line graphs
If we wanted to see whether there is a particular trend in burglaries, we could create a line graph here.
To make a line graph, we need to think about what we will represent on our horizontal (x) axis and what we will represent on our vertical (y) axis. Let’s say that we want to represent the number of burglaries on the Y-axis. OK, so what should we have on our X-axis? That will be whatever we use to fill in the blank in the sentence: number of burglaries per _____________. Let’s say we want to know if there are any changes in the number of burglaries per day. Well, to do this, we will need to count the number of times that each date appears in the data. Remember what this means?
That’s right! Univariate analysis time. Go ahead and use a pivot table to build a frequency table of the Date.of.Occurrence variable. You will eventually end up with something like this:
NOTE: Remember the note we made just above about newer versions (2016+) of Excel automatically grouping our data? It is possible that this has happened to you now, and you have something like this instead:
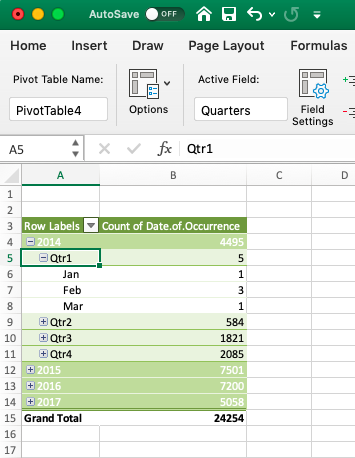
In this case, you will have to ungroup the data. In this case, please right-click anywhere on the pivot table and select the option to “ungroup” your data:
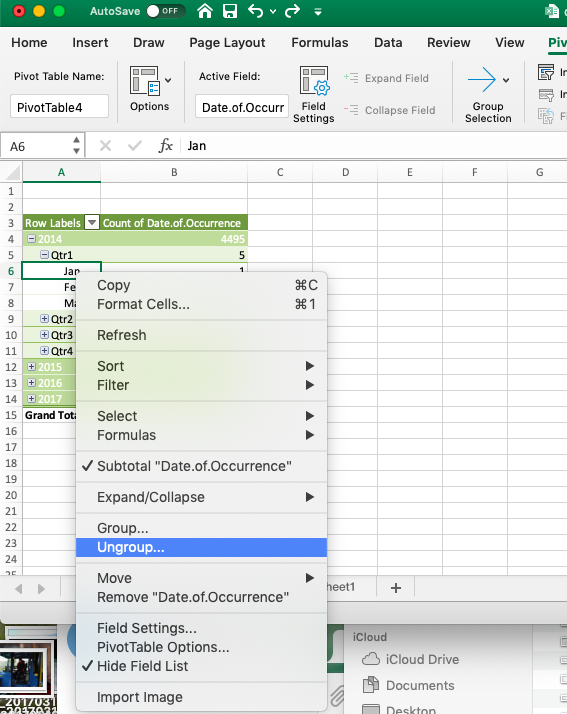
Once you have done this, you will see a pivot table where each date appears only once.
Now, turn this into a line graph. We’ve made several line graphs before, including last week, but never with this many data points. However, the motions are still the same. You highlight your data, select your appropriate chart (line graph), and then add the labels using “Select Data” and populate the ‘Category (X) axis labels’ section in the popup window that appears. If any of this confuses you, re-visit last week’s lab notes about data visualisation.
When all is said and done, you should end up with a chart that looks like this:
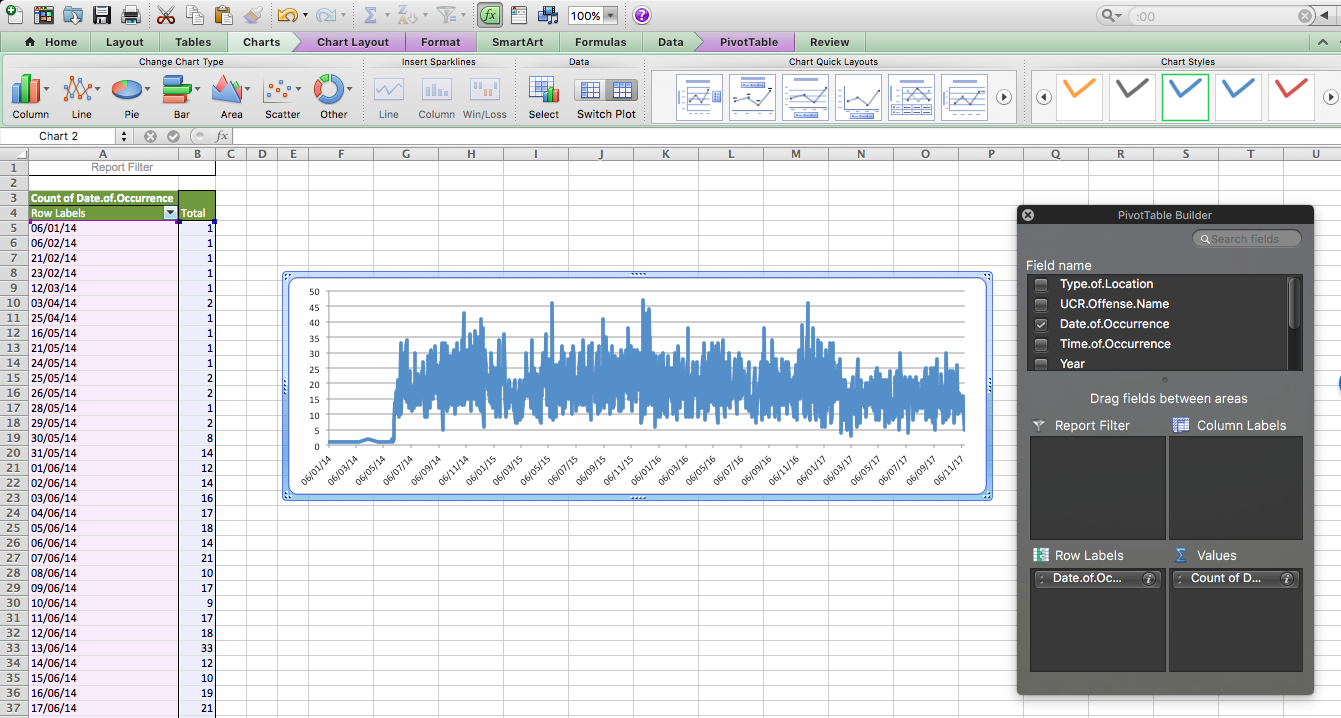
Is residential burglary going up or down in the city of Dallas? It’s not easy to tell from this, is it? The thing with data at these intervals is that there is a lot of day-to-day variation, and what we would refer to as the noise. And in this noise, we can lose sight of the signal.
Signal-to-noise ratio (abbreviated SNR or S/N) is a measure used in science and engineering that compares the level of a desired signal to the level of background noise. While SNR is commonly quoted for electrical signals, it can be applied to any form of signal and is sometimes used metaphorically to refer to the ratio of useful information to false or irrelevant data.
An interesting book to read that talks a lot about how to identify signals within the noise is the aptly named The Signal and the Noise by Nate Silver and if you enjoyed anything about this class, or you enjoyed reading the Tiger that Isn’t text, we would highly recommend it! It can get a bit more technical in places, but it’s got loads of very neat examples and is an entertaining read overall. In this book, the author talks about the need to see past all the noise (the random variation in the data) in order to be able to make predictions (using the signal).
In this case of our burglaries, we would need to be able to somehow look past this variation in day-to-day changes to be able to look at overall trends. For example, we could start to smooth this data, and instead of looking at the number of burglaries each day, begin to consider the average number of burglaries every ten days, which would be something called the 10-point moving average. This would be one approach to smoothing our data. We will return to this later today.
9.6 The time cycle: visualising cyclical variables
I’ve hinted at this throughout the course, that there are special kinds of ordinal categorical variables which are cyclical, meaning that they have a pattern which repeats. Remember back in lab 1, when you were coding the levels of measurement for the variables in the Twitter data we assembled? And we told you that the time of a Tweet, for example, was not a numeric variable; instead, it was ordinal. Well, the hour of the day is a cyclical ordinal variable, as it cycles around. After 23h comes 0h, and not 24, as we would expect from a numeric variable.
How can we best represent this special nature of our variables?
There are also multiple cyclical ways to visualise your data. One approach is to use radar graphs. The graphs below all represent the same page view data for a website across different times of day. Here’s an example by Purna Duggirala that is essentially a bubble chart that uses two clocks side by side:
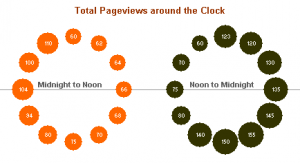
The biggest problem with the chart is the incorrect continuity. A single clock on its own isn’t a continuous range; it’s really only half a range. So the clock on the left is showing 12 am – 12 pm, but when you reach the end of the circle the data doesn’t continue on like the representation shows. Instead you need to jump over to the second clock and continue on around. It’s difficult to see the ranges right around both 12 pm and 12 am since you lose context in one direction or another (and worse, you get the incorrect context from the bordering bubbles).
In a great show of Internet collaboration, the double clock chart spurred some other experimentation. Jorge Camos came up with a polar chart that plots the data on a single “clock face,” showing two 12-hour charts overlaid on top of each other.
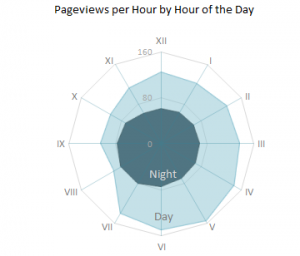
Given that the 12-hour clock is a difficult metaphor to use for a visualization, many people choose to use a 24-hour circle. 24-hour circular charts typically start with midnight at the top of the chart and then proceed clockwise, showing all 24 hours in one 360-degree range. The benefit of a 24-hour circular chart is that the cyclical nature of the data is represented, and the viewer can easily read the continuity at any point on the chart.
A simple example of a 24-hour circle comes from Stamen Design‘s Crimespotting. This isn’t a data-heavy visualization chart since it doesn’t actually show any data other than sunrise and sunset times (instead, its main purpose is as a filtering control). But it’s a good example of the general layout of 24-hour charts, and it’s very clean and well-labelled. You can read about the thinking that went into designing this “time of pie” on Stamen’s blog.
The inspiration for this time selector, which is documented in Tom Carden’s blog post, was the real-life timer control used for automating lights in your house.

This above is known as a radial chart. We will now learn how to build one in Excel. But before we do, we wanted to remind you guys of the story of Florence Nightingale, the original data visualisation pioneer (I spoke about her in the lecture about data visualisation). We know, we know, we covered data visualisation last week, can we please get over it! But it’s one of the most fun aspects of data analysis, so no, we cannot, and now we will remind you again about why Florence Nightingale wasn’t just a famous nurse. She was a famous data pioneer!
This is Florence Nightingale’s ‘Coxcomb’ diagram on mortality in the army:
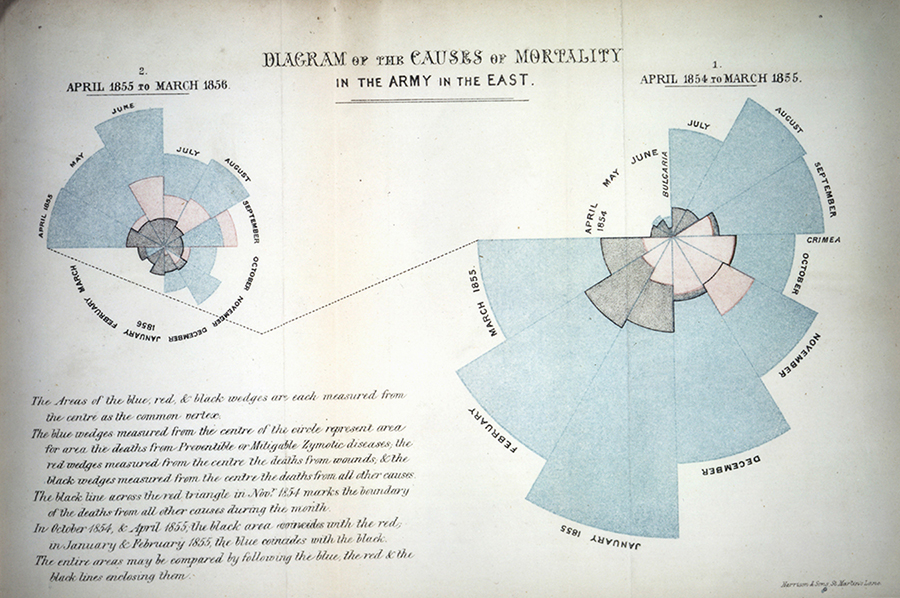
We all have an image of Nightingale - who died over 100 years ago - as a nurse, lady with the lamp, medical reformer and campaigner for soldiers’ health. But she was also a data journalist. After the disasters of the Crimean War, Florence Nightingale returned to become a passionate campaigner for improvements in the health of the British army. She developed the visual presentation of information, including the pie chart, first developed by William Playfair in 1801. Nightingale also used statistical graphics in reports to Parliament, realising this was the most effective way of bringing data to life.
Her report on the mortality of the British Army, published in 1858, was packed with diagrams and tables of data. The Coxcomb chart demonstrates the ratio of British soldiers who died during the Crimean War of sickness rather than of wounds or other causes. Her work changed the course of history, enabling proactive change through data collection. In 1858, Nightingale presented her visualisations to the health department demonstrating the conditions of the hospitals and whose actions resulted in deaths being cut by two-thirds.
9.6.1 Activity 9.7: Visualising cycles: Radar charts
So, how do we make these in Excel? Well, let’s return to our within-day variation in residential burglaries. Let’s visualise when they take place.
To do this, we will first need to create a frequency table of the hour variable. Remember, we are graphing UNIVARIATE ANALYSIS. We are describing one variable in our data, which is the hour variable. To know the frequency of each value of this variable (the number of burglaries in each hour), we must build a pivot table.
Do this, create a pivot table that tells you the frequency of each hour:
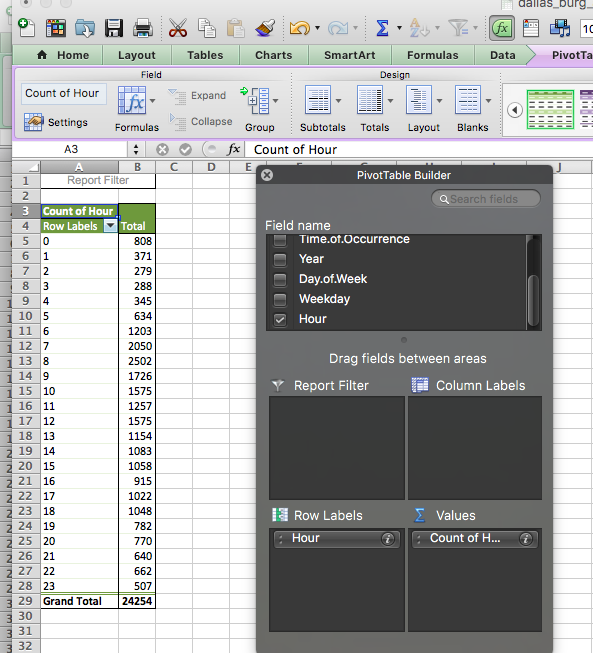
Now highlight the “Total” column, as it represents the number of burglaries in each hour, and this is what you want to graph. Then, from Charts, select “Other” and then “Radar”:
Or, in some cases, it might be under the waterfall chart option (symbolising “other”):
A radar graph will appear something like this:
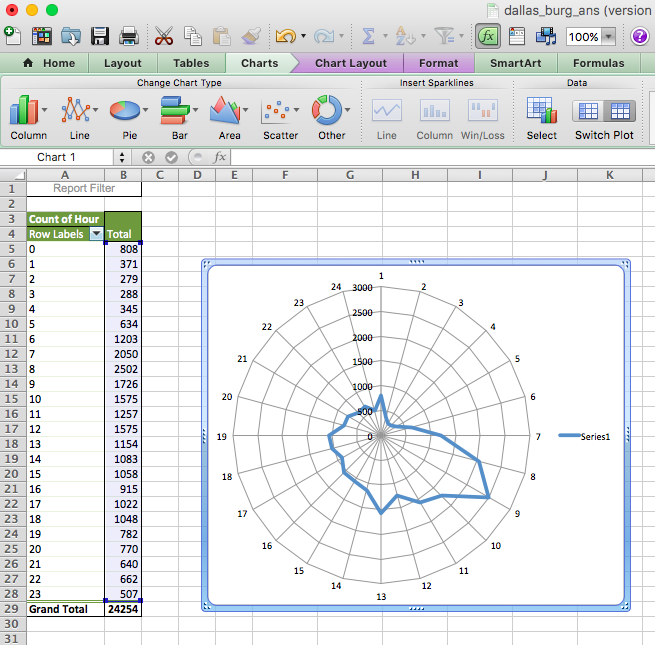
Now, there is something wrong with this graph. Can you spot it? Take a moment now to look… I’ll wait here. Once you have some ideas, discuss them in your groups and write them down!

Did you notice? If not, look again; this time, look at the graph and tell us which hour has the most burglaries. Great, now look at the pivot table. Is it the same hour? (hint: no).
Why is this? Well, our axes are not actually labelled! Remember, to label your axes, do as you did in the line graph: right-click on the graph, “Select Data…” and populate the ‘Category (X) axis labels’ section in the popup window that appears with the hours. Now your graph should make sense:
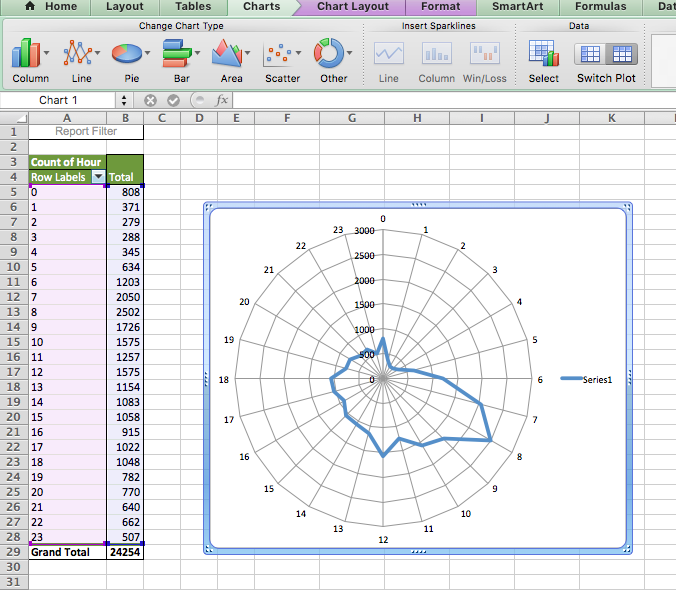
Much better. Clearly, residential burglaries happen in the morning and in the day, and much less so at night. But is this any different between weekends and weekdays?
Now, we are introducing a second variable. By now, you should know that this means that to answer this question, we will need bivariate analysis. So, create a bivariate table by dragging the weekday variable which we created earlier into the “Column Labels” box in the pivot table options. This will create a crosstab for you:
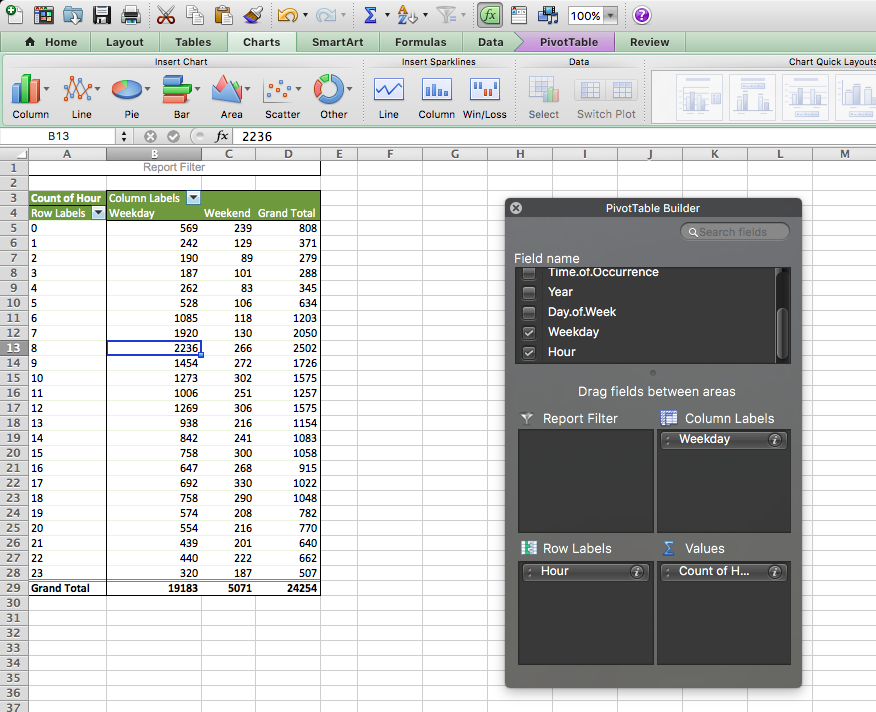
Now select the values for the “Weekday” column, and again for charts, choose Other > Radial:
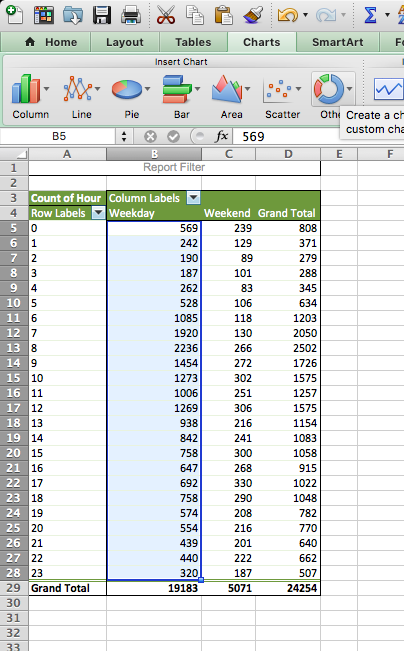
A chart will appear, showing you only the weekday burglaries. Now, right-click this chart and select the “Select Data…” option:
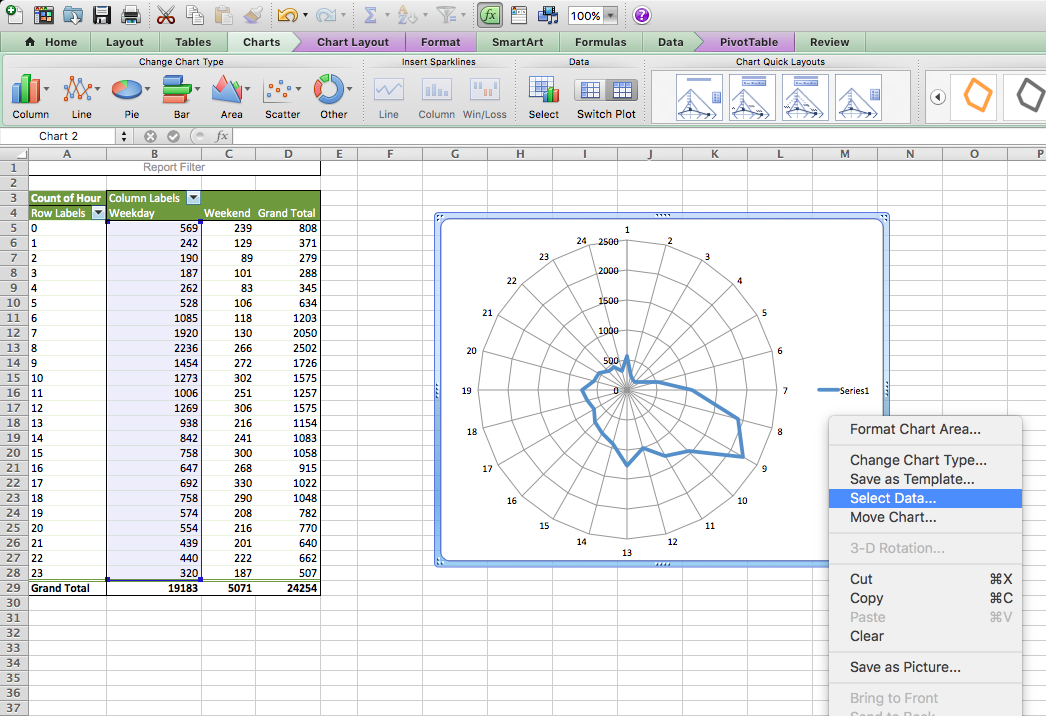
First, label your current data. Do this by clicking in the textbox next to the “Name:” label and then clicking on the column header (cell B4):
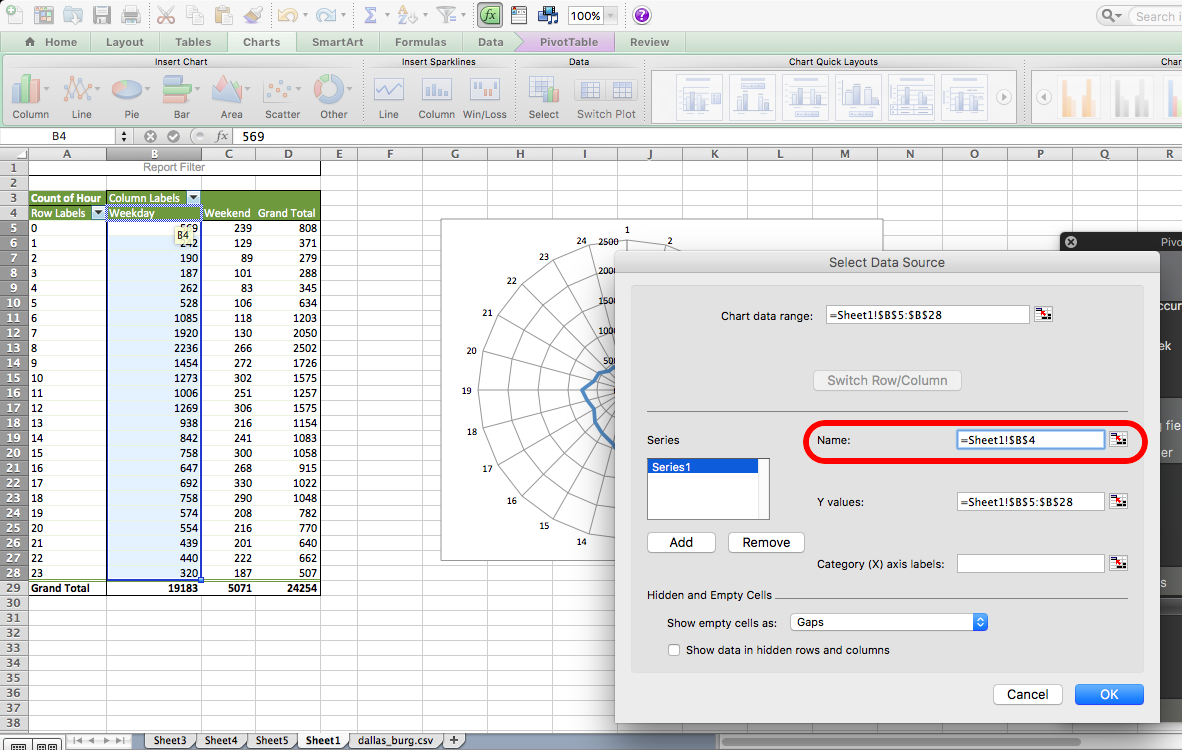
Then, add the correct labels by clicking on the box next to “Category (X) axis labels” and selecting the hours in the “Row Labels” column.
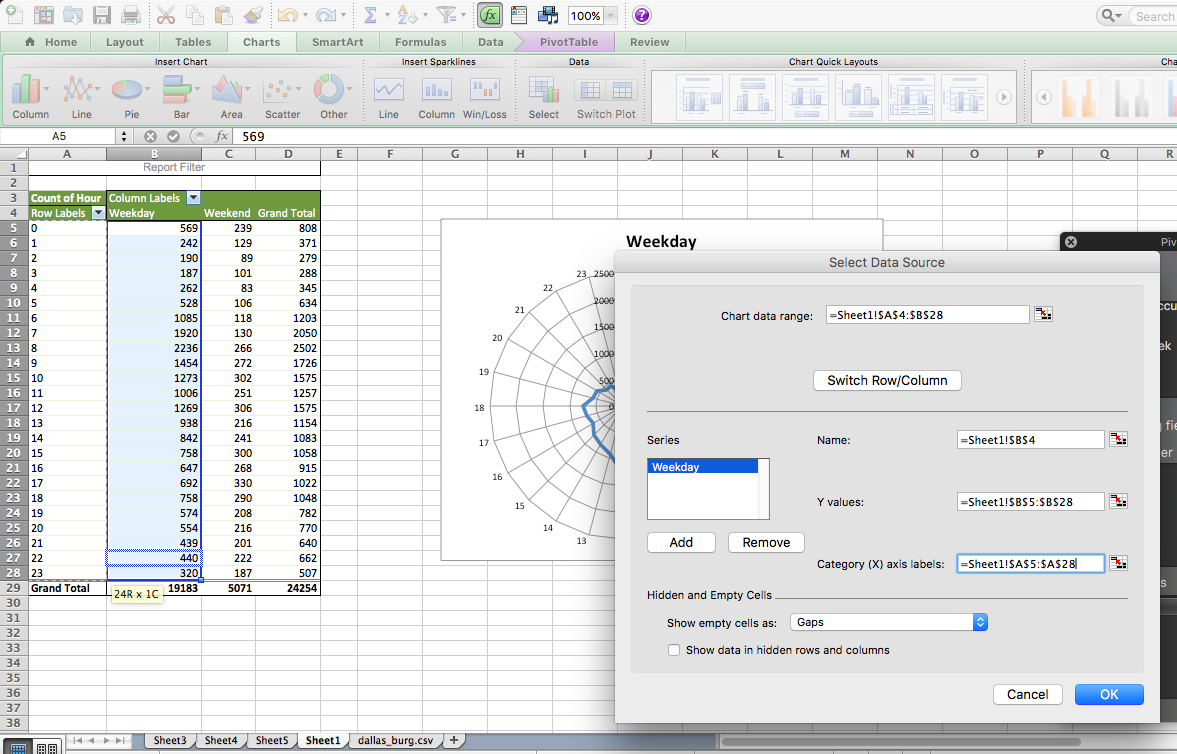
Now, add the weekend burglaries. Do this the same way we added multiple lines last week. You click on the “Add” button, and you put the name in the textbox next to “Name:” and the values in the text box next to the “Y-values” box. This time, you can leave “Category (X) axis labels” empty, as the previous series already populate it:
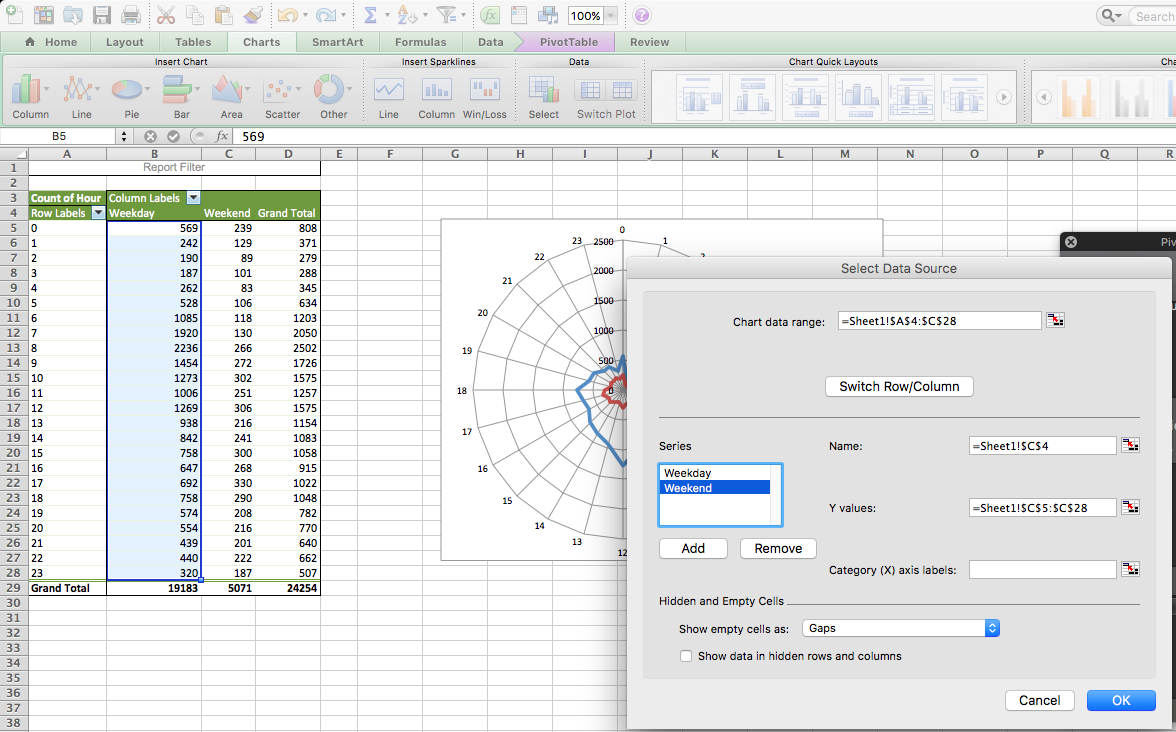
Ta-daa, here is your 2-variable radial graph.
One issue, though. Can you think of it?
No? Well, look at how tiny the circle is for the weekend. This is because of the problem that we discussed earlier; there are simply many more burglaries on the weekdays. If we want to look at how within-day patterns differ between weekends and weekdays, this graph isn’t necessarily the best approach. Instead, we should look at percentage distribution instead of count.
To do this, change the pivot table to display per cent instead of count. A reminder of how to do this: you click on the little i (or arrow on a PC) to bring up a popup window, on which you select options:
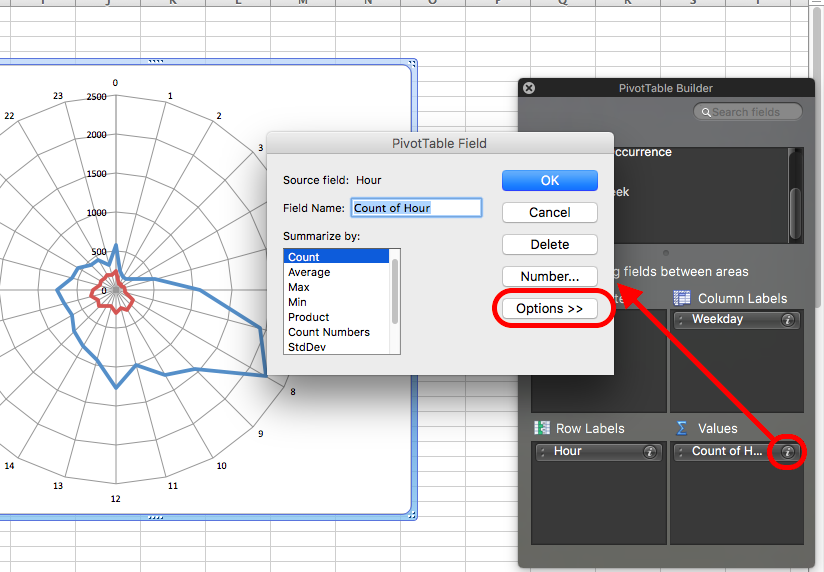
This brings up a menu where you can select what to “show data as”. Choose % of column (because we want to know the percentage of weekday crimes in each hour and the percentage of weekend crimes in each hour, so our 100% are our columns; we are looking at column percentages):
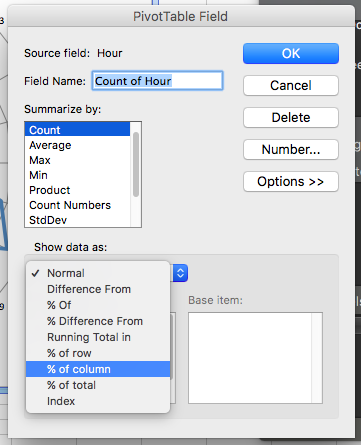
For doing this on a PC, the options are slightly different for getting the percentages for weekday/weekend burglaries. Need to go to the tab called “Show Values As” and then select % of Column:
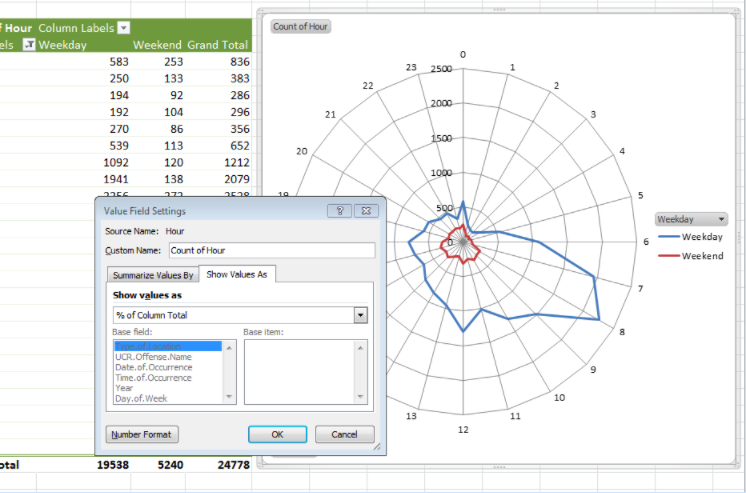
And finally, ta-daa, you have a radial graph that helps you compare the within-day temporal patterns of residential burglary between weekdays and weekends.
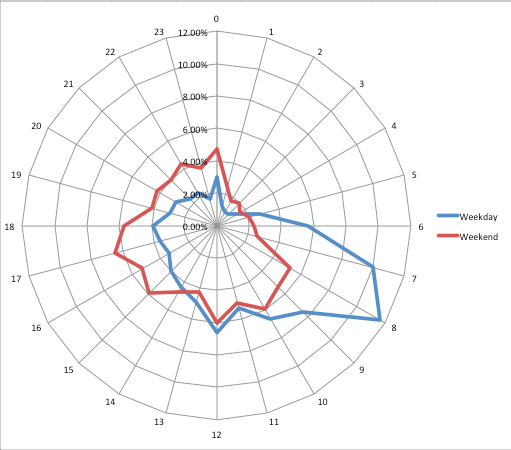
Now we can talk about what is the temporal distribution of burglary within the day and how this pattern is different between weekdays and weekends. Think about how these might map onto people’s routine activities. What time do you think most people leave to go to work in the morning? Could that explain the spike in weekday early hours, which we don’t see in the weekend chart? Hmm hmm!
9.7 Bivariate analysis
Another way we might want to apply bivariate analysis to temporal data is to look at patterns within the day and within the week or within the week and within the month. This allows us to drill down with more granularity to see when specific crimes are happening. One way to do this is to appeal to our cross tabs from back in week three and use heatmaps to visualise these.
9.7.1 Activity 9.8: Heatmaps
Heatmaps visualise data through variations in colouring. When applied to a tabular format, Heatmaps are useful for cross-examining multivariable data by placing variables in the rows and columns and colouring the cells within the table. Heatmaps are good for showing variance across multiple variables, revealing any patterns, displaying whether any variables are similar to each other, and detecting if any correlations exist between them.
Typically, all the rows are one category (labels displayed on the left or right side), and all the columns are another category (labels displayed on the top or bottom). The individual rows and columns are divided into subcategories, which all match up with each other in a matrix. The cells contained within the table either contain colour-coded categorical data or numerical data based on a colour scale. The data contained within a cell is based on the relationship between the two variables in the connecting row and column.
A legend is required alongside a Heatmap in order for it to be successfully read. Categorical data is colour-coded, while numerical data requires a colour scale that blends from one colour to another in order to represent the difference in high and low values. A selection of solid colours can be used to represent multiple value ranges (0-10, 11-20, 21-30, etc), or you can use a gradient scale for a single range (for example, 0 - 100) by blending two or more colours together. Refer back to what we learned about colour last week in data visualisation.
Because of their reliance on colour to communicate values, Heatmaps are a chart better suited to displaying a more generalised view of numerical data, as it’s harder to accurately tell the differences between colour shades and to extract specific data points from (unless of course, you include the raw data in the cells).
Heatmaps can also be used to show the changes in data over time if one of the rows or columns is set to time intervals. An example of this would be to use a Heatmap to compare the temperature changes across the year in multiple cities to see where the hottest or coldest places are. The rows could list the cities to compare, the columns contain each month, and the cells would contain the temperature values.
Let’s make a heatmap for burglary from a crosstab, looking at the frequency of burglary across days of the week and hours of the day.
You can know, by the way the question is phrased, that your task here will require a bivariate analysis. To produce this, we will need a pivot table. So let’s create our crosstab with a pivot table, where we have the day of the week in columns and the hour of the day in the rows:
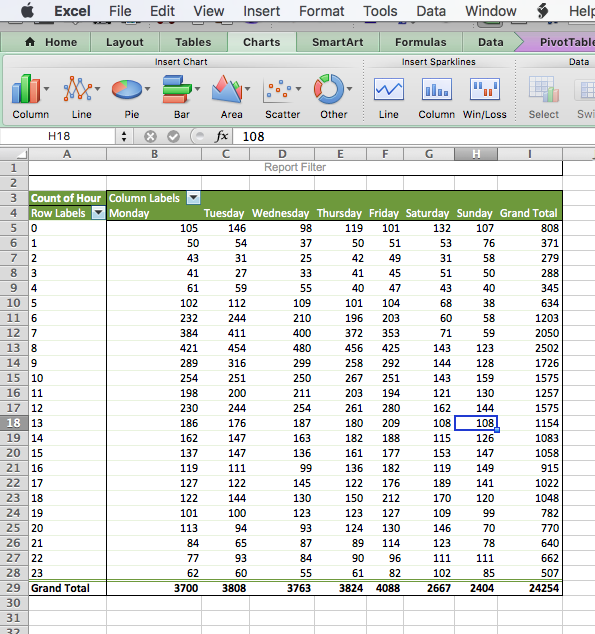
Now, this tells you all the information you want to know, but there are many cells with many numbers, and it’s not immediately obvious where we should be looking. A heatmap (via conditional formatting) creates an option for us to nudge people to find the high and low values in this table.
To implement this, highlight the values in your table:
Then, find the conditional formatting tab and select a colour scheme that works for you. Remember to consider whether red values should be high or low. Is a high number good? Or is it bad?
In this case, red is bad because it means more burglaries! Select this colour scheme, and as if by magic, our table will now be highlighted in the form of a heatmap:
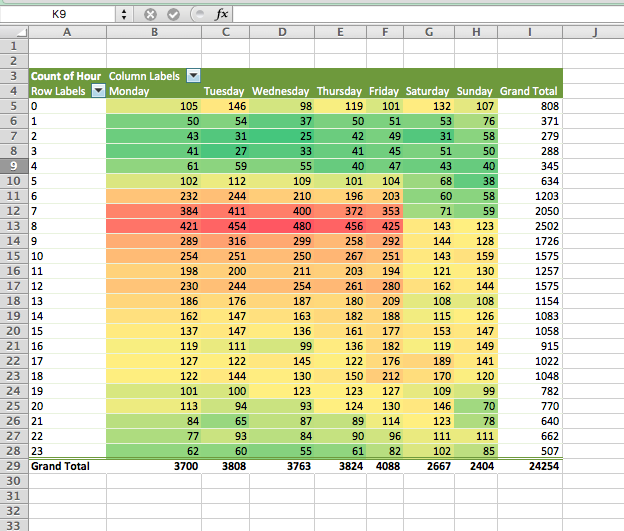
Now your eyes are immediately drawn to where the high values are, which apparently is Monday to Friday, 7 and 8 AM. We can see that on Saturdays and Sundays, even burglars want a lie-in, and therefore, you see the low green burglary rate creep up later than on weekdays. Exciting stuff!
Do remember, though, what we learned about colour coding, and make sure you consider your colourblind audiences when presenting such data!
9.7.2 More charts?
The Gantt chart is also a way to visualise the passage of time or the tasks you must complete as this time passes. You learned in the session covering research design about Gantt charts, which are essentially horizontal bar charts showing work completed in a certain period of time with respect to the time allocated for that particular task.

It is named after the American engineer and management consultant Henry Gantt, who extensively used this framework for project management. We covered how to do these in the research design session; please refer back to those if you are not sure how to make them any more…!
There are also some non-conventional line-graph-based timelines. While these appear initially like linear representations, it’s actually possible for these to loop back and reverse in time, making them slightly different. For example, this one about gas prices and driving practices, or this one about driving safely demonstrate this approach quite neatly.
You could also have a stacked line chart to represent time:
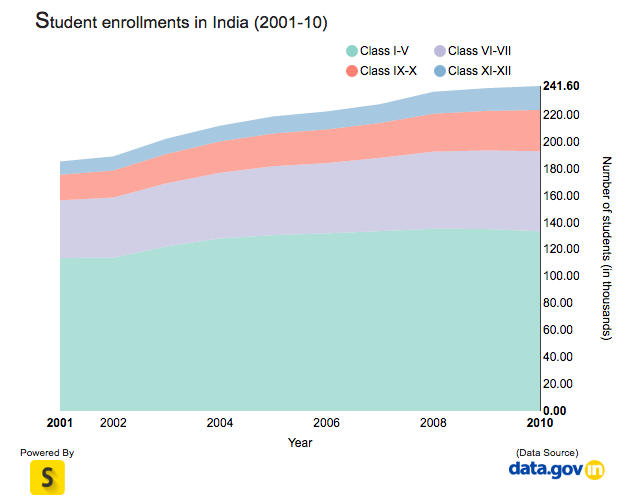
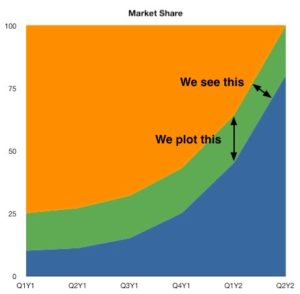
Stacked area charts are useful to show how both a cumulative total and individual components of that total changed over time.
The order in which we stack the variables is crucial because there can sometimes be a difference in the actual plot versus human perception. The chart plots the value vertically, whereas we perceive the value to be at the right angles relative to the general direction of the chart. For instance, in the case below, a bar graph would be a cleaner alternative.
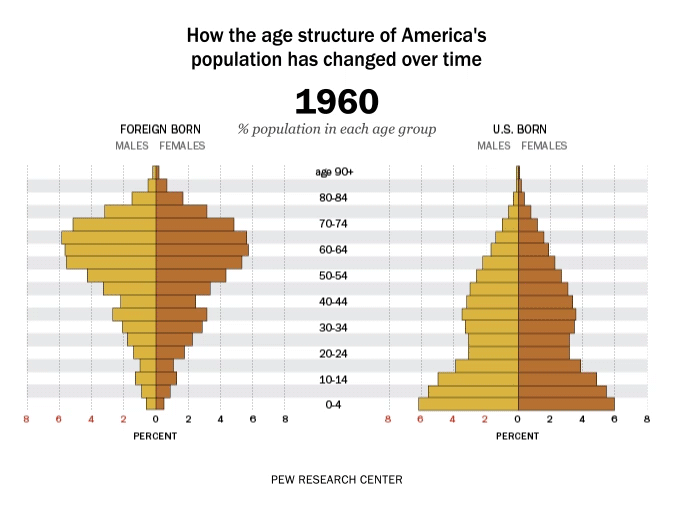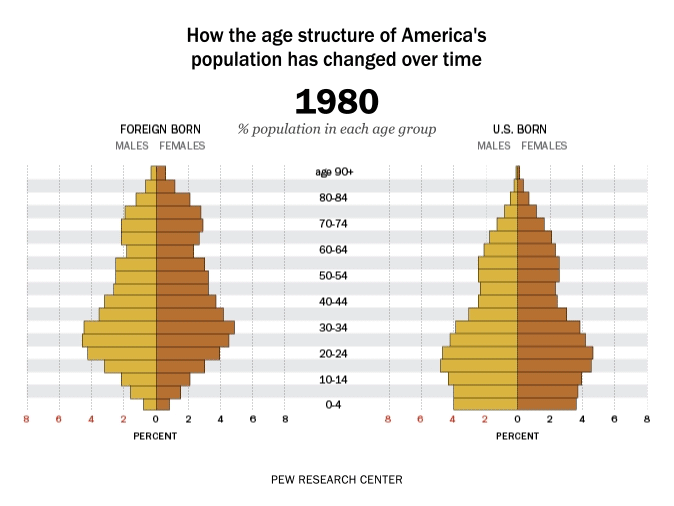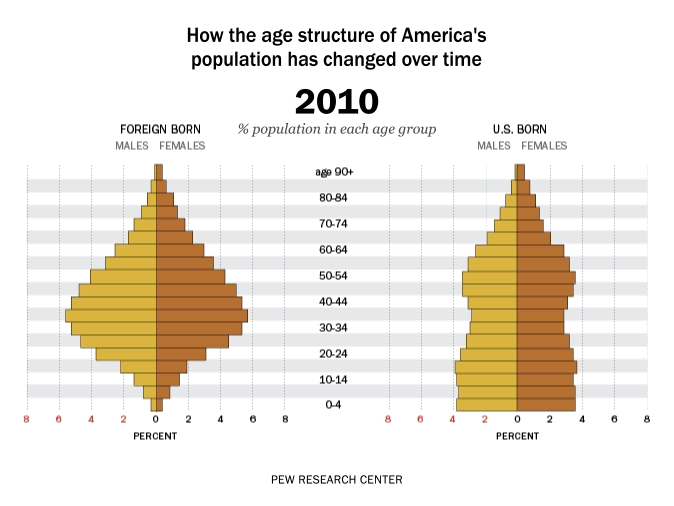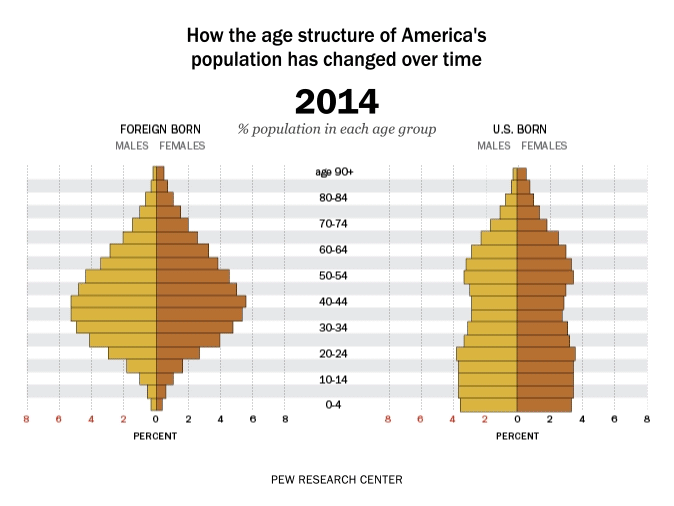
Time is dynamic, and as a result there are many dynamic visualisations of time as well. For example, it is possible to build a gif as a graph output, with each measurement in time being one frame. This example, which represents time as frames in a gif, shows how the percent of the US population by age group has changed and is predicted to change over time:
Similarly, Hans Rosling, who you might remember from the Joy of Stats video, was known for his dynamic representation of time, using videos and gifs:
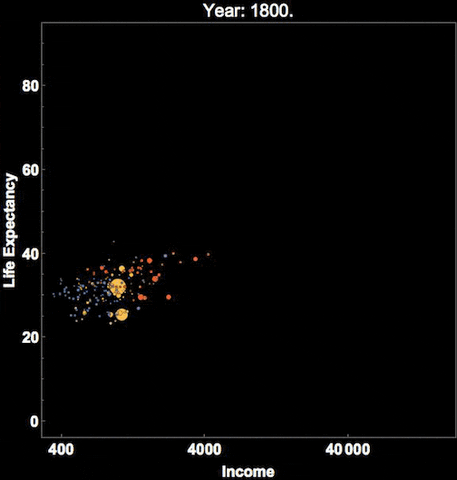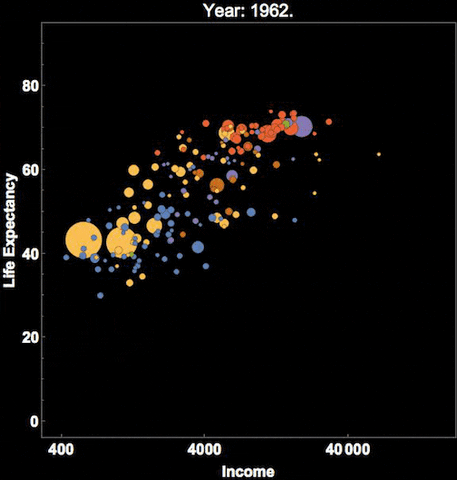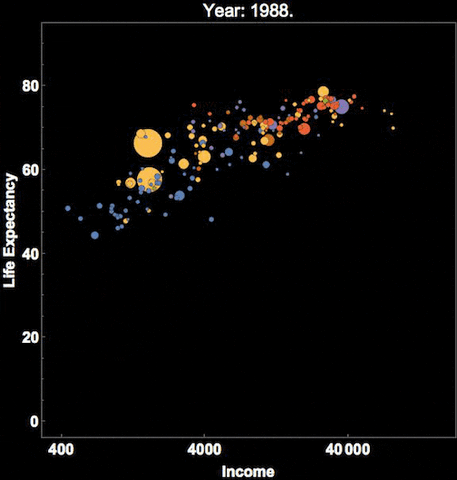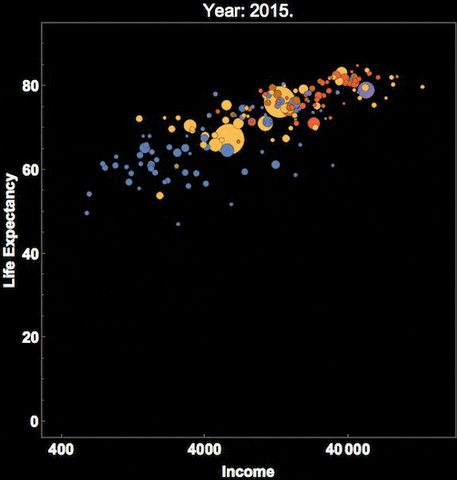
You can see that there are many cool ways to represent time, and I’ve shown you only a few. We hope you are interested in exploring more!
9.8 Time series
When reading and discussing temporal time analysis, you will hear such data referred to as a time series. A Time Series is an ordered sequence of values of a variable at equally spaced time intervals. For example, when we aggregate our burglaries data to dates, then we have a series of observations (each day in our data set) and a corresponding number of burglaries which take place on each day. It becomes a time series of burglaries.
Time Series Analysis is an analytic technique that uses such a sequence of data points measured at successive, uniform time intervals (such as each day, like in the burglary data) to identify trends and other characteristics of the data. For example, a time series analysis may be used to study our data on burglary rate over time, and based on the patterns we find, it may be able to predict future crime trends.
So, what makes time series data special? Well, all-time series data have three basic parts:
- A trend component; this is the overall trend we might observe in the data, e.g. is burglary going up, going down, or staying constant?
- A seasonal component; this is the seasonal variation, a repeated fluctuation pattern, such that we saw with different crimes in the lecture videos, e.g. that burglary varies within the week, we expect a peak in weekday sand a dip in weekends as we saw above.
- A random component; we have to account for this element of random fluctuation, the “noise” on our data. Sometimes crime goes up or down due to random events - a prolific burglar has broken her arm, a homeowner who may have otherwise been burgled has a child fall sick and has to stay home from school for a week, and even less discernable, less specific reasons, there is always an element of random variation in data, and we always must be conscious of this “noise” from which we must discern the signal.
Trends are often masked because of the combination of these components – especially the random noise! It is our task, with temporal analysis to make sense of these components, separate them, and extract meaning from our data.
When we extract these elements, two types of patterns are important: - The trends, which can be linear or non-linear (i.e., upwards or downwards or both (quadratic)); and - The seasonal effects which follow the same overall trend but repeat themselves in systematic intervals over time.
We care less about random noise, only to quiet it, but not to find patterns in it, as it is a random error.
There is a whole area of research and data analysis which focuses on making sense of time series data. Here, we will cover only a brief overview so you are aware of them. To manipulate and extract meaning from time series data, researchers and analysts turn to time series models.
The usage of time series models can serve to:
- To help reveal or clarify trends by obtaining an understanding of the underlying forces and structure that produced the observed data
- To forecast future patterns of events by fitting a model – To test the impact of interventions
One approach we will explore here is smoothing our time series data. Smoothing data removes random variation and shows trends and cyclic components. Inherent in the collection of data taken over time is some form of random variation. There exist methods for reducing or cancelling the effect due to random variation. Smoothing can reveal more clearly the underlying trend, seasonal and cyclic components.
In this course we will explore smoothing in order to answer questions of the first option from those above, ‘To help reveal or clarify trends by obtaining an understanding of the underlying forces and structure that produced the observed data’. In particular, we will look into producing moving averages. You should also know about the existence of smoothing techniques, and the sophisticated method for revealing trends is known as seasonal decomposition. However, we will not be performing these ourselves today.
9.9 Moving averages
Calculating a moving average is a technique to get an overall idea of the trends in a data set. It is achieved by taking an average of any subset of numbers. The moving average is extremely useful for forecasting long-term trends. You can calculate it for any period of time. For example, if you have sales data for a twenty-year period, you can calculate a five-year moving average, a four-year moving average, a three-year moving average and so on. Stock market analysts will often use a 50 or 200-day moving average to help them see trends in the stock market and (hopefully) forecast where the stocks are headed.
We have learned about the mean (or average) in this course and how it represents the “middling” value of a set of numbers. The moving average is exactly the same, but this average is calculated several times for several subsets of data. For example, if you want a two-year moving average for a data set from 2000, 2001, 2002 and 2003, you would find averages for the subsets 2000/2001, 2001/2002 and 2002/2003.
Moving averages are used to see seasonal fluctuations or to gauge the direction of the current trend. Every type of moving average is a mathematical result that is calculated by averaging a number of past data points. Once determined, the resulting average is then plotted onto a chart in order to allow analysts to look at smoothed data rather than focusing on the day-to-day fluctuations that are inherent in time series. To help aid understanding of trends, moving averages are usually plotted and are best visualized.
The simplest form of a moving average, appropriately known as a simple moving average (SMA), is calculated by taking the arithmetic mean of a given set of values like the ones described above. For example, to calculate a basic 10-day moving average for the number of burglaries mentioned above, you would add up the total number of burglaries from the past 10 days and then divide the result by 10. If an analyst wishes to see a 50-day average instead, the same type of calculation would be made, but it would include the number of burglaries over the past 50 days. The resulting average takes into account the past 50 data points in order to give traders an idea of how an asset is priced relative to the past 50 days.
Perhaps you’re wondering why this tool is called a “moving” average and not just a regular mean. The answer is that as new values become available, the oldest data points must be dropped from the set and new data points must come in to replace them. Thus, the data set is constantly “moving” to account for new data as it becomes available.
There is a more detailed explanation using the example of stock prices here: Moving Averages: What Are They?. OK, you say, why do we care about stock prices when we are criminologists? Well, anyone looking at something over time should be interested in calculating this. Moving averages are a general method for reducing random fluctuation in any time series by recomputing the value for every data point based on the average of preceding time periods. This can apply to calculating, for example, burglaries over time.
Here is a real-world example:
Paul Barclay and colleagues evaluated the effects of bike patrols on auto theft from a large commuter parking lot outside Vancouver, British Columbia. Vehicle theft dropped after the response, but it had been dropping for several weeks prior to the bike patrols since the implementation of a publicity campaign that preceded the bike patrols. In this case, an anticipatory effect may have added a great deal to the overall effectiveness of the patrols. Though a moving average was used to smooth out random variation, the drop in thefts between the beginning of the publicity and the beginning of the bike patrols is too large to be due to data smoothing.
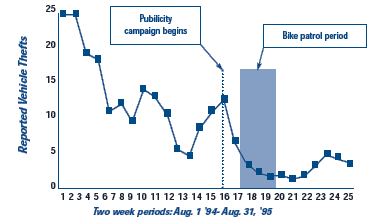 Source: Barclay, Paul and colleagues (1996) “Preventing Auto Theft in Suburban Vancouver Commuter Lots: Effects of a Bike Patrol.” Crime Prevention Studies, volume 6, Monsey, NY: Criminal Justice Press.
Source: Barclay, Paul and colleagues (1996) “Preventing Auto Theft in Suburban Vancouver Commuter Lots: Effects of a Bike Patrol.” Crime Prevention Studies, volume 6, Monsey, NY: Criminal Justice Press.
Evidently, we can use this moving average to tease out signal (what is happening) from noise (random fluctuations in our data/measurement).
9.9.1 Activity 9.9 Hand calculate the moving average
It is important that you understand the concept of what we are covering before we move on to the Excel part. To de-mystify what we are actually doing, sitting down with a pen and paper and working out what Excel does behind the scenes can really help with this. So, in this activity, we really want you to take time and watch this video on how to calculate moving averages by hand and follow along. In your groups, you might want to watch the video together and follow along or individually and discuss afterwards. When you have finished watching, make some notes about what you have just learned.
9.9.2 Activity 9.10: Moving average in Excel
With the previous activity, we now have the experience of calculating a moving average by hand. However on larger data sets, you won’t be able to do this by hand. So, let’s learn how to calculate the moving average in Excel. Initially, we will practice on a smaller data set in order to help see through the process and link what we just did by hand to what we’re about to do here. For this, we will be using some example data on temperature measurement. You can download this data from Blackboard under Learning Materials > Module 9 > Data for labs and homework folder. It should be called mov_avg_temp_example.xlsx. Then, you can use it to follow the tutorial below.
We will need the Data analysis toolpak for this one, so look back to previous weeks where we used it or all the way back to week 1 when we installed it in case you’ve forgotten all about this.
In our toy data set, someone has collected daily temperature information. The temperature fluctuates both seasonally and with random noise (especially in Manchester…!), so to make sense of the trends in temperature, we want to calculate the three-day moving average — the average of the last three days — as part of some simple weather forecasting. To calculate moving averages for this data set, take the following steps.
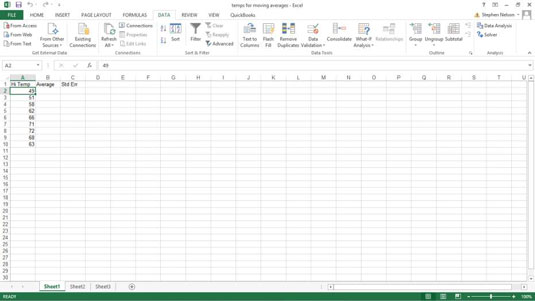
To calculate a moving average, first click the Data tab’s Data Analysis command button.
When Excel displays the Data Analysis dialog box, select the Moving Average item from the list and then click OK.
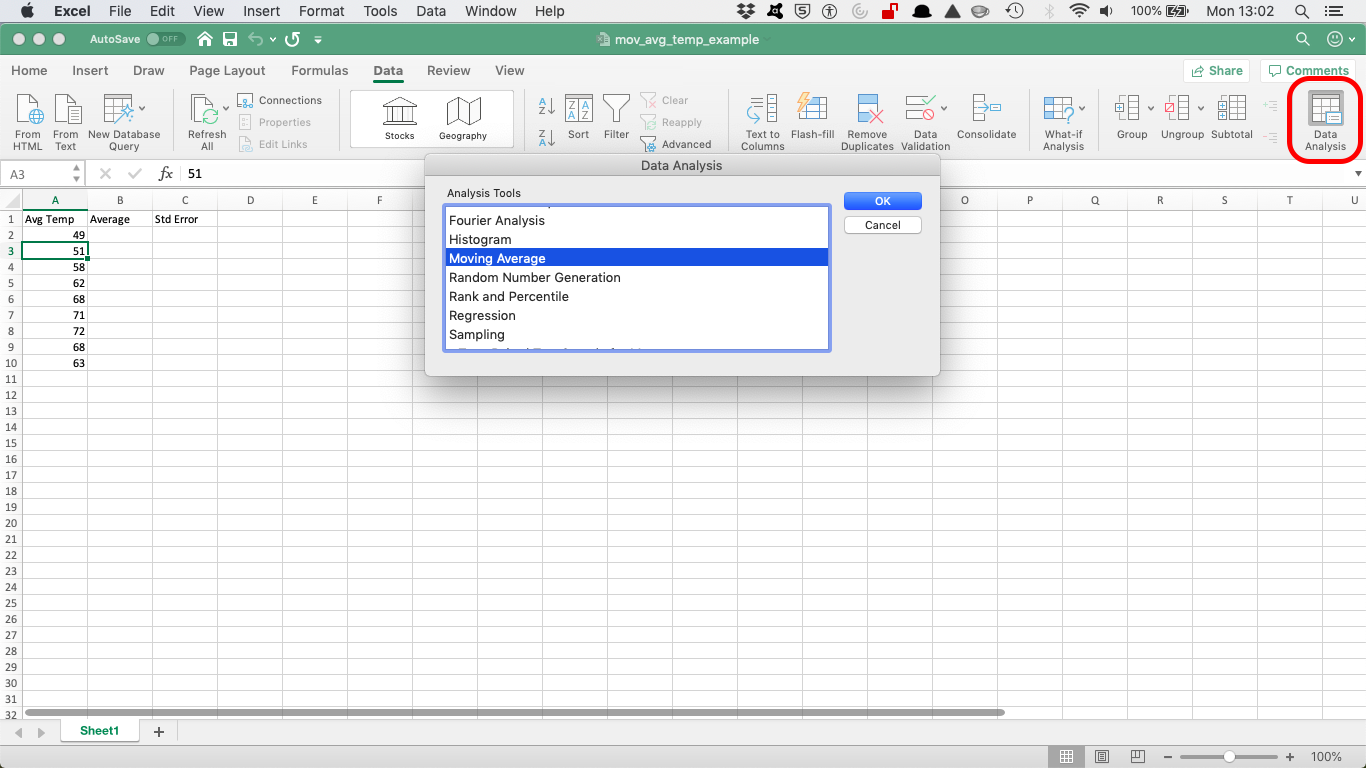
Identify the data that you want to use to calculate the moving average.
Click in the Input Range text box of the Moving Average dialogue box. Then, identify the input range, either by typing a worksheet range address or by using the mouse to select the worksheet range. Your range reference should use absolute cell addresses. An absolute cell address precedes the column letter and row number with $ signs, as in $A$1:$A$10. This should be familiar by now!
Once you have the correct cells in the ‘Input Range’, make sure to tick the box that says “Labels in First Row” (this means that the first row (A1) has the name (or label) of the column, rather than a value to be used in the calculations):
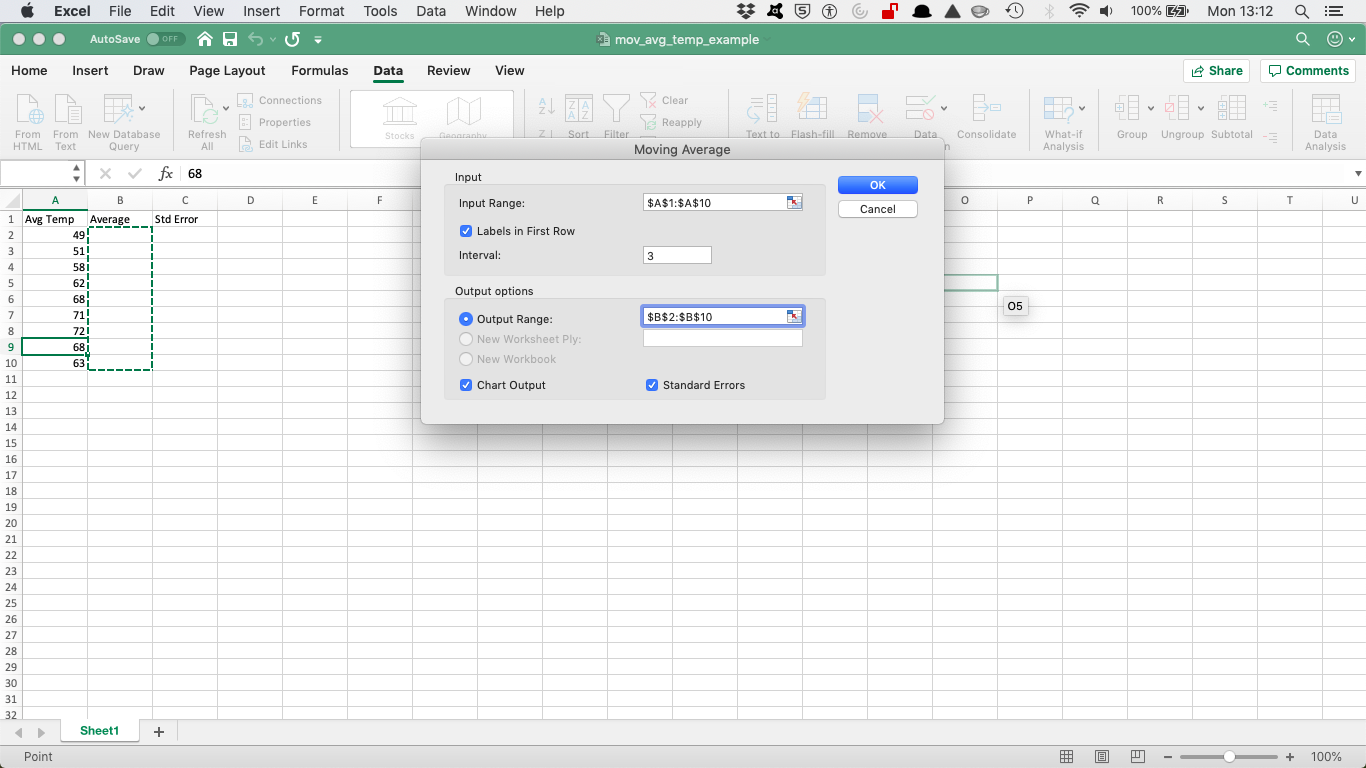
In the Interval text box, tell Excel how many values to include in the moving average calculation. You can calculate a moving average using any number of values. By default, Excel uses the most recent three values to calculate the moving average. To specify that some other number of values be used to calculate the moving average, enter that value into the Interval text box. Here, let’s enter 3 (which is the default, but why not be specific).
Finally, tell Excel where to place the moving average data. Use the Output Range text box to identify the worksheet range into which you want to place the moving average data. In the worksheet example, the moving average data has been placed into the worksheet range B2:B10 (the next column over from the A column).
After you finish specifying what moving average information you want to be calculated and where you want it placed, click OK.
Then you should see something like this:
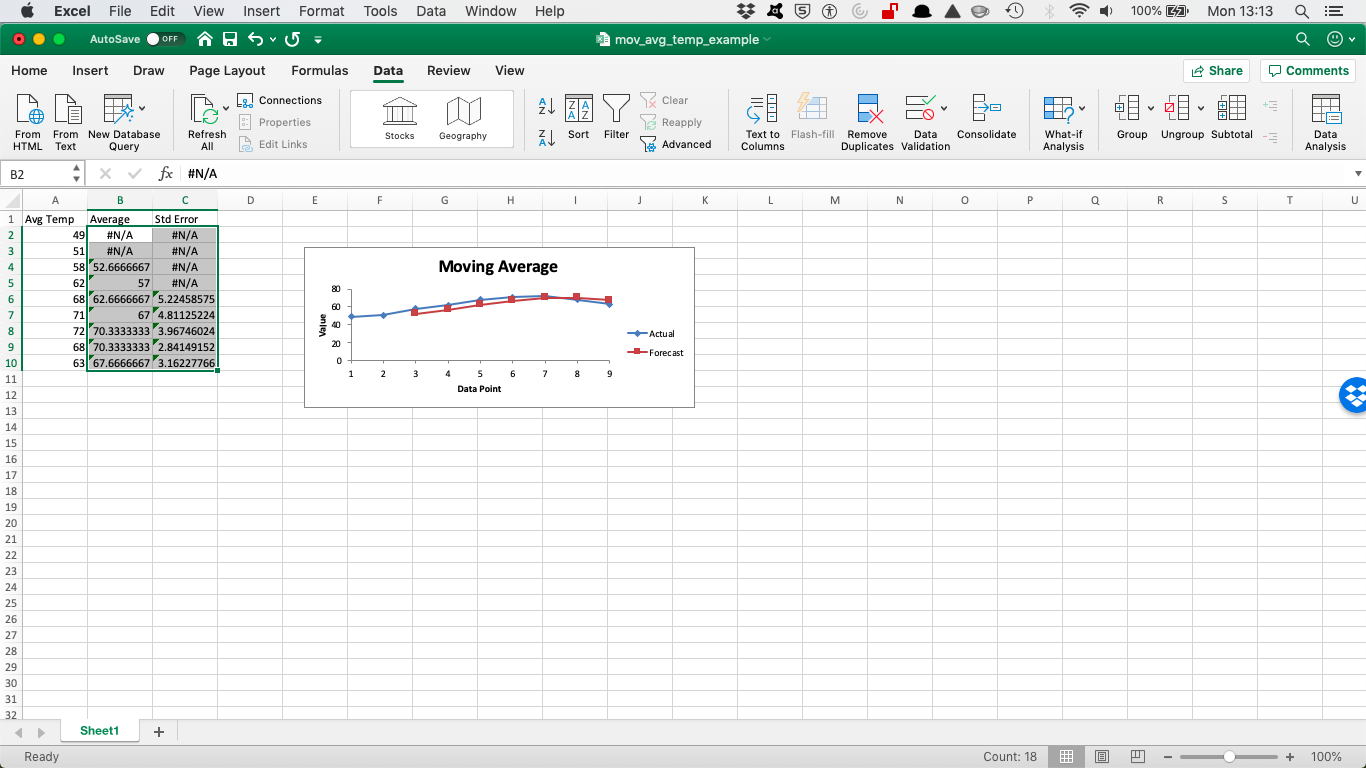
Note: If Excel doesn’t have enough information to calculate a moving average for a standard error, it places the error message into the cell. You can see several cells that show this error message as a value. This is normal because there is nothing to calculate from. You saw this in the previous exercise as well when the video mentioned the “gaps”.
So that’s how you calculate a simple moving average in Excel. If you want another toy example to play around with, you may try again by following the steps in this tutorial here
If you’d like to apply this to our burglary data to see what we can get out of that, you’re very welcome to as well. We won’t go into that now, as we’ve done enough today, but here’s our Moving Average chart for burglary for only 2015 year from our Dallas data set using 30 days:
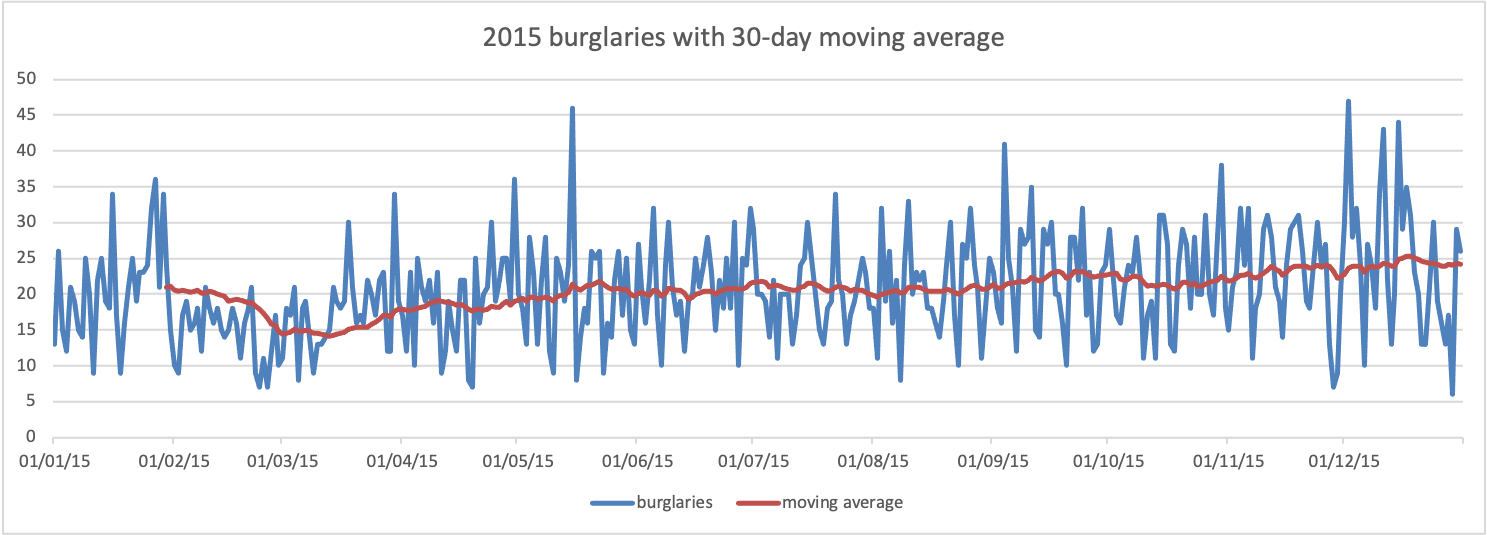
So that’s about it. If you’re feeling very adventurous, you can have a look at seasonal decomposition in Excel and one more in-depth learning about moving average and soothing techniques in Excel as well.
9.10 Summary
In sum, you should now be able to begin to make sense of temporal data in criminology. You should know how to extract variables from a date variable, how to aggregate into meaningful intervals, how to best visualise temporal trends, and how the approach of the moving average works in order to be able to find the signal amidst the noise. You should be comfortable with the following terms:
- time-series
- seasonality
- cyclical variable
- radar graph
- heatmap
- moving average
- smoothing
- signal & noise
- trend, seasonality, and randomness
- how to use the following formulas
- text()
- year()
- hour()