Chapter 6 Studying spatial point patterns
6.1 What we’ll do today
We have now covered quite a bit! You’ve learnt about spatial objects and various formats in which they come and are stored by R, how to produce maps using a variety of packages, and also provided you with a brief introduction to common spatial operations. In what remains of the semester we are going to shift the emphasis and start focusing a bit more on spatial statistics. First we will focus on techniques that are used to explore and analyse points in a geographical space and in subsequent sessions we will cover techniques that are used to analyse spatial data when our unit of analysis are polygons (e.g., postal code areas, census areas, police beats, etc).
We will introduce a new R package called spatstat, that was developed for spatial point pattern analysis and modelling. It was written by Adrian Baddeley and Rolf Turner. There is a webpage dedicated to this package. The thickest book in my library, at 810 pages, is dedicated to this package. So as you can imagine the theory and practice of spatial pattern analysis is something one could devote an entire course to. You can get a pdf document used in a course the authors of this package develop here. In our course we are only going to provide you with an introductory practical entry into this field of techniques. If this package is not installed in your machine, make sure you install it before we carry on.
We will be using the following packages today:
readxl
janitor
sf
ggplot2
dplyr
spatstat
terra
leaflet
6.2 Getting the data
This week we will work with some slightly larger data sets than before: we will have one year’s worth of police-recorded crime data for Greater Manchester Police from the police.uk website.
Within that, we will focus on burglary in the Fallowfield area. The code below has already been explained and used in previous sessions, so we won’t go over the detail again. But rather than cut and paste automatically, try to remember what each line of code is doing. If you have any questions about it, do ask in the lab, remember - practice makes perfect!
By the way, the police data for Manchester we have used in previous sessions correspond to only one month of the year. Here we are using a full year worth of data, so the data import will take a bit longer.
We’ll also be using a geojson shape file of wards. From this we will select Fallowfield ward specifically.
You can get both the geojson file of wards and the excel file of crimes from Blackboard. Save to your computer, and remember to put it in the right place for the project! Here I saved mine into the “data” subfolder.
#Read a geojson file with Manchester wards (remember we learned about geojson files in week 4).
manchester_ward <- st_read("data/manchester_wards.geojson")## Reading layer `manchester_wards' from data source
## `/Users/user/Desktop/resquant/crime_mapping_textbook/data/manchester_wards.geojson'
## using driver `GeoJSON'
## Simple feature collection with 32 features and 5 fields
## Geometry type: POLYGON
## Dimension: XY
## Bounding box: xmin: 378833.2 ymin: 382620.6 xmax: 390350.2 ymax: 405357.1
## Projected CRS: OSGB36 / British National Grid#step1: create a new object that only has the 'fallowfield' ward
df1 <- manchester_ward %>%
filter(wd22nm == "Fallowfield")
#step2: change coordinate systems
fallowfield <- st_transform(df1, 4326)
#step3: get rid of objects we no longer need
rm(manchester_ward, df1)
#step4: Read Greater Manchester police data
#or you can use this link:"https://www.dropbox.com/s/rs43mg8equy1zu5/gmp_crimes_2021.zip?dl=1"
#(see week5, 5.1.1.2. Activity 2, if you forget how to do!)
crimes <- read_xlsx("data/gmp_crimes_2021.xlsx") %>% clean_names()
#step5: filter Burglary
burglary <- filter(crimes, crime_type == "Burglary")
#step6: transform the dataframe with crime information into a sf object
burglary_spatial <- st_as_sf(burglary, coords = c("longitude", "latitude"),
crs = 4326)
#step7: select only the crimes that take place within the space defined by the Ward boundaries
# intersection
bur_fal <- st_intersects(fallowfield, burglary_spatial)
# subsetting
bur_fal <- burglary_spatial[unlist(bur_fal),]
#step8: again remove things we don't need
rm(crimes, burglary)Now we have all our data cleaned and all our files prepared. Let’s see the results!
In the point pattern analysis literature each point is often referred to as an event and these events can have marks, attributes or characteristics that are also encoded in the data. In our spatial object one of these marks is the type of crime (although in this case it’s of little interest since we have filtered on it).
6.2.1 Activity 1: Getting the data into spatstat: the problem with duplicates
So let’s start using spatstat. The first thing we need to do is to transform our sf object into a ppp object which is how spatstat likes to store its point patterns. A ppp object needs two ingreatiesnts: 1: the points (xy coordinates) and 2: the observation window (the polygon that defines where points could have been observed).
Because point pattern methods rely on distances, we do this in a projected CRS in metres (British National Grid, EPSG:27700).
Now, since a point pattern is defined as a series of events in a given area, or window, of observation, it is extremely important to precisely define this window. In spatstat the function owin() is used to set the observation window. We can do this using the function as.owin(). Here are the steps:
Then we use the as.owin function to define the window.
Now, use the class function and print the window object to check that this worked:
## [1] "owin"## window: polygonal boundary
## enclosing rectangle: [383705.3, 386682.3] x [393780.5, 394986.1] unitsNow that we have created the window as an owin object let’s get the points. First we will extract the coordinates from our sf point data into a matrix:
Then we use the ppp function to create the ppp (point pattern) object using the information from our matrix and the window that we created.
## Warning: data contain duplicated points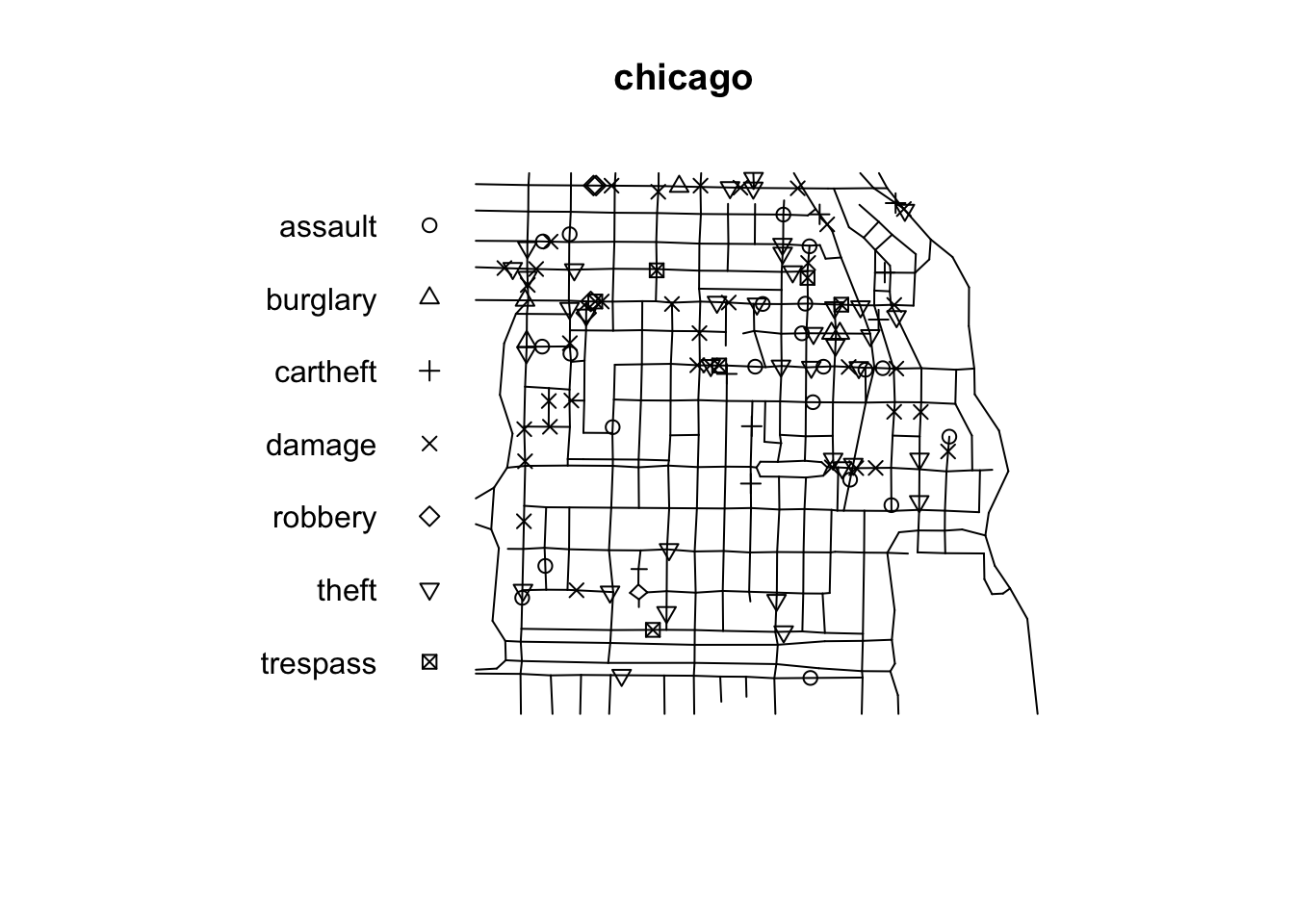
Notice the warning message about duplicates. In spatial point pattern analysis an issue of significance is the presence of duplicates. The statistical methodology used for spatial point pattern processes is based largely on the assumption that processes are simple, that is, that the points cannot be coincident. That assumption may be unreasonable in many contexts (for example, the literature on repeat victimisation indeed suggests that we should expect the same households to be at a higher risk of being hit again). Even so the point (no pun intended) is that “when the data has coincidence points, some statistical procedures will be severely affected. So it is always strongly advisable to check for duplicate points and to decide on a strategy for dealing with them if they are present” (Baddeley et al., 2016: 60).
We can check the duplication in a ppp object with the following syntax:
## [1] TRUETo count the number of coincidence points we use the multiplicity() function. This will return a vector of integers, with one entry for each observation in our dataset, giving the number of points that are identical to the point in question (including itself).
If you want to know how many locations have more than one event you can use:
## [1] 334That’s quite something. 334 points here share coordinates.
In the case of crime, as we have hinted some of this may be linked to the nature of crime itself, repeat victimisation. However, this pattern of duplication is fairly obvious across all crime categories in the police.uk website.
This is due to the way in which spatial anonymisation of police.uk data is carried out. This is done using geomasking, whereby there exist a pre-determined list of points that each crime event gets “snapped” to its nearest one. So, the coordinates provided in the open data are not the exact locations of crimes, but they come from a list of points generated for purposes of data publication. You can see the details here. This process is likely inflating the amount of duplication we observe, because each snap point might have many crimes near it, resulting in those crimes being geo-coded to the same exact location. So keep in mind when analysing and working with this data set that it is not the same as working with the real locations. If you are interested in the effects of this read the paper Tompson, Johnson, Ashby, Perkins & Edwards (2015) UK open source crime data: accuracy and possibilities for research, Cartography and Geographic Information Science, 42:2, 97-111, DOI: 10.1080/15230406.2014.972456.
What to do about duplicates in spatial point pattern analysis is not always clear. You could simply delete the duplicates, but of course that may ignore issues such as repeat victimisation. You could also use jittering, which will add a small perturbation to the duplicate points so that they do not occupy the exact same space. Which again, may ignore things like repeat victimisation. Another alternative is to make each point “unique” and then attach the multiplicites of the points to the patterns as marks, as attributes of the points. Then you would need analytical techniques that take into account these marks.
If you were to be doing this for real you would want access to the real thing, not this public version of the data and then go for the latter solution suggested above. We don’t have access to the source data, so for the sake of simplicity, so that we can illustrate how spatstat works we will instead add some jittering to the data. The first argument for the function is the object (bur_ppp), ‘retry’ asks whether we want the algorithm to have another go if the jittering places a point outside the window (we want this so that we don’t loose points), and the ‘drop’ argument is used to ensure we get a ppp object as a result of running this function (which we do).
Notice the difference with the original plot. Can you see how the circumferences do not overlap perfectly now?
6.2.2 Activity 2: Inspecting our data with spatstat
This package supports all kind of exploratory point pattern analysis. One example of this is quadrant counting, which you learned about in the video prep for this week. One could divide the window of observation into quadrants and count the number of points into each of these quadrants.
For example, if we want 4 quadrants along the X axis and 3 quadrants along the Y axis we could used those parameters in the quadratcount() function.
Then we just use standard plotting functions from R base.
Q <- quadratcount(jitter_bur, nx = 4, ny = 3)
plot(jitter_bur)
plot(Q, add = TRUE, cex = 2) #cex = size of text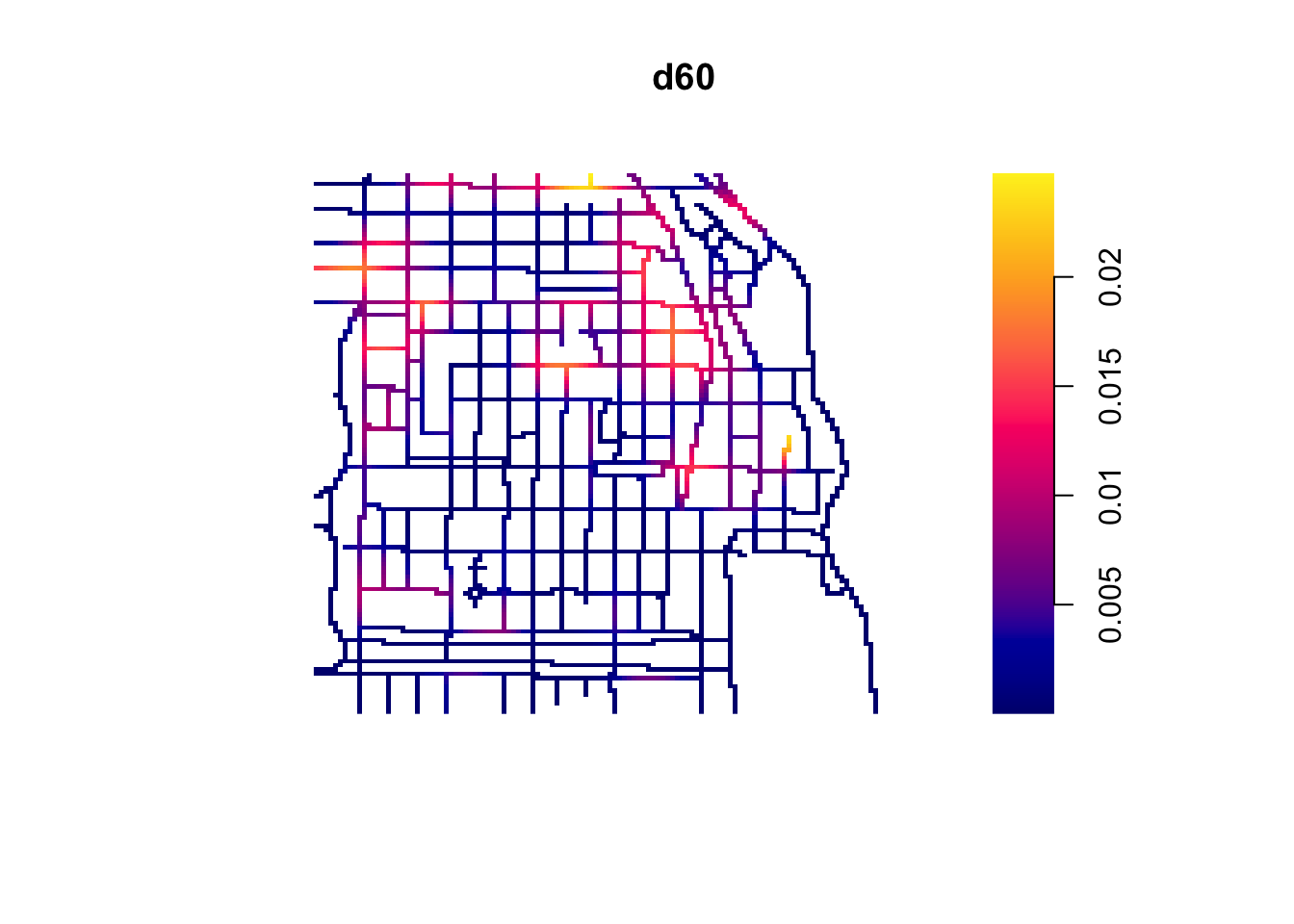
In the video lectures for this week, Luc Anselin introduced the notion of complete spatial randomness (CSR for short). When we look at a point pattern process the first step in the process is to ask whether it has been generated in a random manner. Under CSR, points are independent of each other and have the same propensity to be found at any location. We can generate data that conform to complete spatial randomness using the rpoispp() function. The r at the beginning is used to denote we are simulating data (you will see this is common in R) and we are using a Poisson point process, a good probability distribution for these purposes. Let’s generate 277 points in a random manner:
random <- rpoispp(277)
plot(random)
Q <- quadratcount(random, nx = 4, ny = 3)
plot(Q, add = TRUE, cex = 2)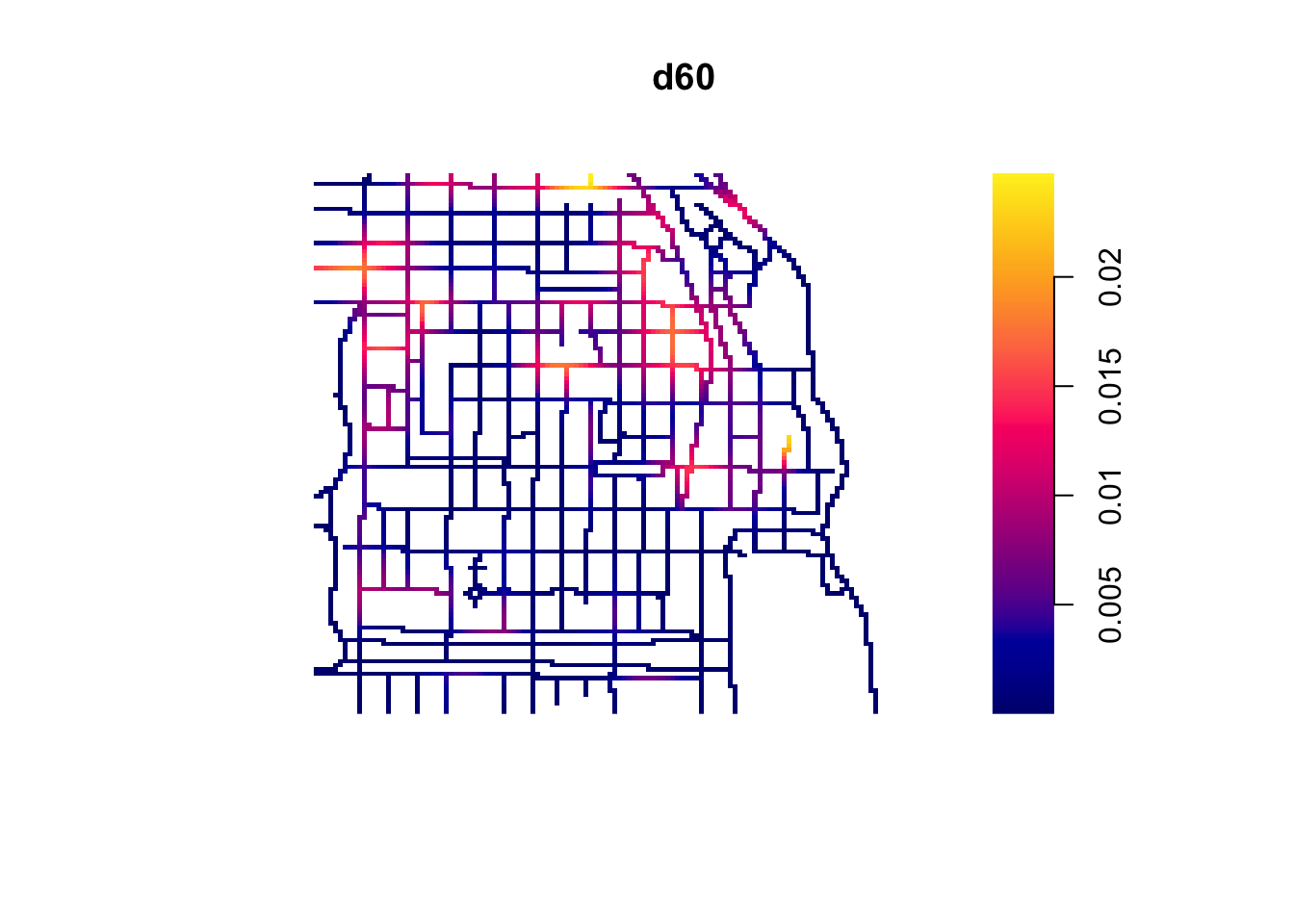
You will notice that the points in a homogeneous Poisson process are not ‘uniformly spread’: there are empty gaps and clusters of points. Also, once you display the ‘quadratcount’ on the plot, the number of points in each area is similar unlike the burglary pattern in Fallowfield. Run the previous command a few times. You will see the map generated is different each time.
In classical literature, the homogeneous Poisson process (CSR) is usually taken as the appropriate ‘null’ model for a point pattern. Our basic task in analysing a point pattern is to find evidence against CSR. We can run a Chi Square test to check this. So, for example:
##
## Chi-squared test of CSR using quadrat counts
##
## data: jitter_bur
## X2 = 100.77, df = 4, p-value < 2.2e-16
## alternative hypothesis: two.sided
##
## Quadrats: 5 tiles (irregular windows)Observing the results we see that the p value is well below conventional standards for rejection of the null hypothesis (\(\alpha = 0.05\)). Observing our data of burglary in Fallowfield would be extremely rare if the null hypothesis was true. We can then conclude that the burglary data is not randomly distributed in the observed space. But no cop nor criminologist would really question this. They would rarely be surprised by your findings! We do know that crime is not randomly distributed in space.
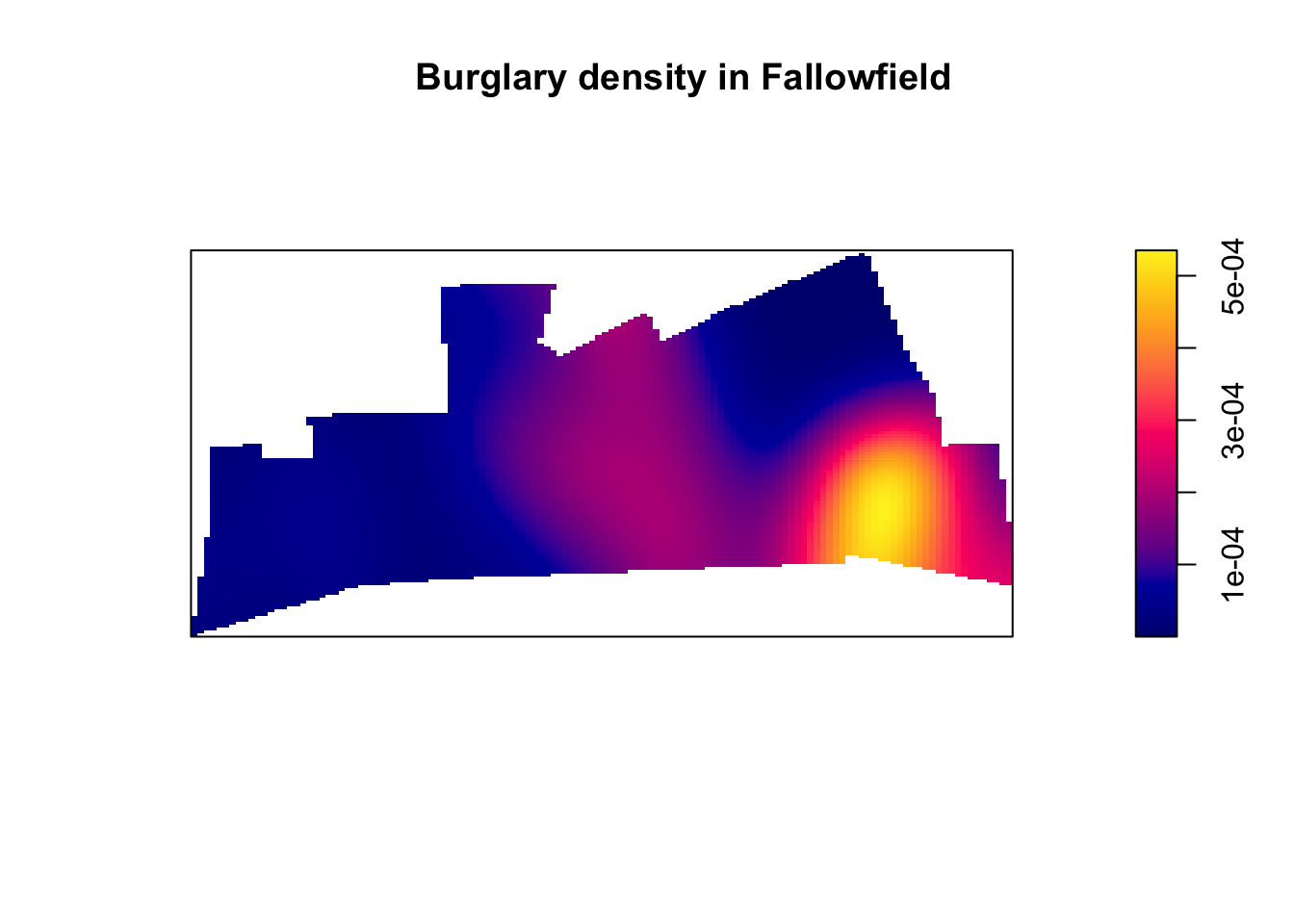
6.3 Density estimates
In the presentations by Luc Anselin and the recommended reading materials we introduced the notion of density maps. Kernel density estimation involves applying a function (known as a “kernel”) to each data point, which averages the location of that point with respect to the location of other data points. The surface that results from this model allows us to produce isarithmic maps, also referred to in common parlor as heatmaps. Beware though, cartographers really dislike this common parlor. We saw this kind of maps when covering the various types of thematic maps.
Kernel density estimation maps are very popular among crime analysts. According to Chainey (2012), 9 out of 10 intelligence professionals prefer it to other techniques for hot spot analysis. As compared to visualisations of crime that relies on point maps or thematic maps of geographic administrative units (such as LSOAs), kernel density estimation maps are considered best for location, size, shape and orientation of the hotspot (Chainey, 2012). Spencer Chainey and his colleagues (2008) have also suggested that this method produces some of the best prediction accuracy. The areas identified as hotspots by KDE (using historical data) tend to be the ones that better identify the areas that will have high levels of crime in the future. Yet, producing these maps (as with any map, really) requires you to take a number of decisions that will significantly affect the resulting product and the conveyed message. Like any other data visualisation technique they can be powerful, but they have to be handled with great care.
Essentially this method uses a statistical technique (kernel density estimation) to generate a smooth continuous surface aiming to represent the density or volume of crimes across the target area. The technique, in one of its implementations (quartic kernel), is described in this way by Eck and colleagues (2005):
- “a fine grid is generated over the point distribution;
- a moving three-dimensional function of a specified radius visits each cell and calculates weights for each point within the kernel’s radius. Points closer to the centre will receive a higher weight, and therefore contribute more to the cell’s total density value;
- and final grid cell values are calculated by summing the values of all kernel estimates for each location”
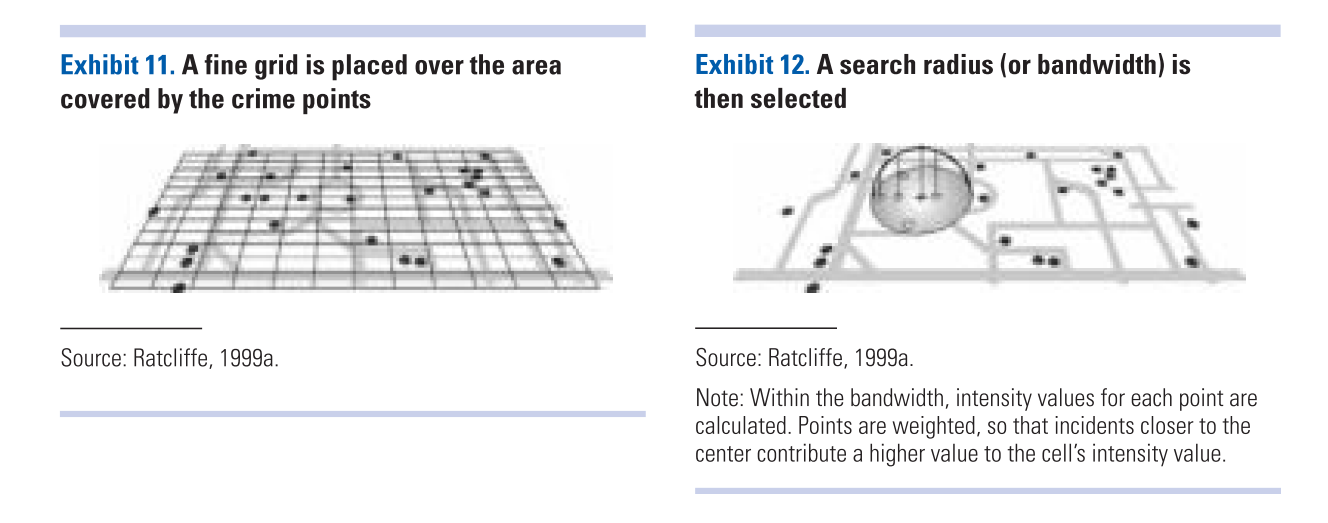 (Reproduced from Eck et al. 2012)
(Reproduced from Eck et al. 2012)
The values that we attribute to the cells in crime mapping will typically refer to the number of crimes within the area’s unit of measurement. We don’t have the time to elaborate further on this technique now, but if you did the required reading you should have at least a notion of how this works.
6.3.1 Activity 3: Density maps
Let’s produce one of these density maps:
## [1] "im"
The density function is estimating a kernel density estimate. Density is nothing but the number of points per unit area. This method computes the intensity continuously across the study area and the object returns a raster image.
To perform this analysis in R we need to define the bandwidth of the density estimation, which basically determines the area of influence of the estimation. There is no general rule to determine the correct bandwidth; generally speaking if the bandwidth is too small the estimate is too noisy, while if bandwidth is too high the estimate may miss crucial elements of the point pattern due to oversmoothing (Scott, 2009).
The key argument to pass to the density method for point pattern objects is sigma=, which determines the bandwidth of the kernel. In spatstat the functions bw.diggle(), bw.ppl(), and bw.scott() can be used to estimate the bandwidth according to different methods. The helpfiles recommend the use of the first two. These functions run algorithms that aim to select an appropriate bandwith.
## sigma
## 2.064384## sigma
## 22.87258## sigma.x sigma.y
## 255.32712 98.63856You can see the Diggle algorithm gives you the narrower bandwith. We can test how they work with our dataset using the following code:
par(mfrow=c(2,2))
plot(density.ppp(jitter_bur, sigma = bw.diggle(jitter_bur),edge=T),
main = paste("diggle"))
plot(density.ppp(jitter_bur, sigma = bw.ppl(jitter_bur),edge=T),
main=paste("likelihood cross-validation"))
plot(density.ppp(jitter_bur, sigma = bw.scott(jitter_bur)[2],edge=T),
main=paste("scott 1"))
plot(density.ppp(jitter_bur, sigma = bw.scott(jitter_bur)[1],edge=T),
main=paste("scott 2"))
Baddeley et (2016) suggest the use of the bw.ppl() algorithm because in their experience it tends to produce the more appropriate values when the pattern consists predominantly of tight clusters. But they also insist that if your purpose is to detect a single tight cluster in the midst of random noise then the bw.diggle() method seems to work best.
Apart from selecting the bandwidth we also need to specify the particular kernel we will use. In density estimation there are different types of kernel (as illustrated below):
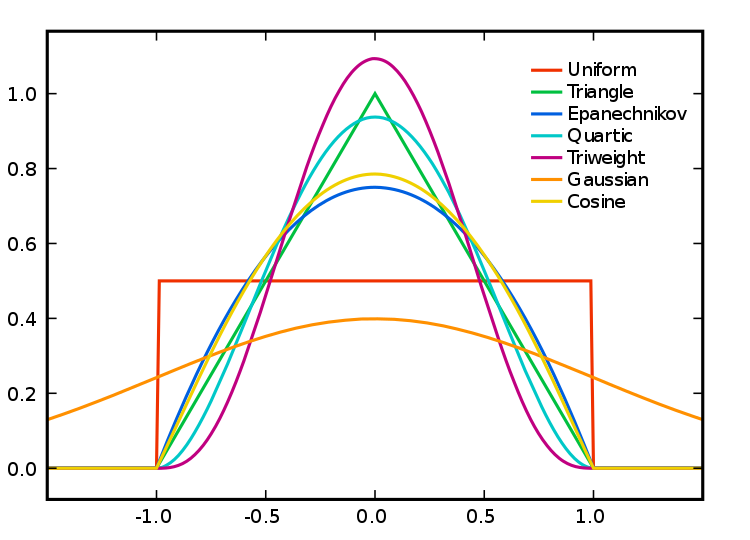 Source: wikepedia
Source: wikepedia
You can read more about kernel types in the Wikipedia entry. This relates to the type of kernel drawn around each point in the process of counting points around each point. The use of these functions will result in slightly different estimations. They relate to the way we weight points within the radius: “The normal distribution weighs all points in the study area, though near points are weighted more highly than distant points. The other four techniques use a circumscribed circle around the grid cell. The uniform distribution weighs all points within the circle equally. The quartic function weighs near points more than far points, but the fall off is gradual. The triangular function weighs near points more than far points within the circle, but the fall off is more rapid. Finally, the negative exponential weighs near points much more highly than far points within the circle and the decay is very rapid.” (Levine, 2013: 10.10).
Which one to use? Levine (2013) produces the following guidance: “The use of any of one of these depends on how much the user wants to weigh near points relative to far points. Using a kernel function which has a big difference in the weights of near versus far points (e.g., the negative exponential or the triangular) tends to produce finer variations within the surface than functions which weight more evenly (e.g., the normal distribution, the quartic, or the uniform); these latter ones tend to smooth the distribution more. However, Silverman (1986) has argued that it does not make that much difference as long as the kernel is symmetrical. Chainey (2013) suggest that in his experience most crime mappers prefer the quartic function, since it applies greater weight to crimes closer to the centre of the grid. The authors of the CrimeStat workbook (Smith and Bruce, 2008), on the other hand, suggest that the choice of the kernel should be based in our theoretical understanding of the data generating mechanisms. By this they mean that the processes behind spatial autocorrelation may be different according to various crime patterns and that this is something that we may want to take into account when selecting a particular function. They provide a table with some examples that may help you to understand what they mean:
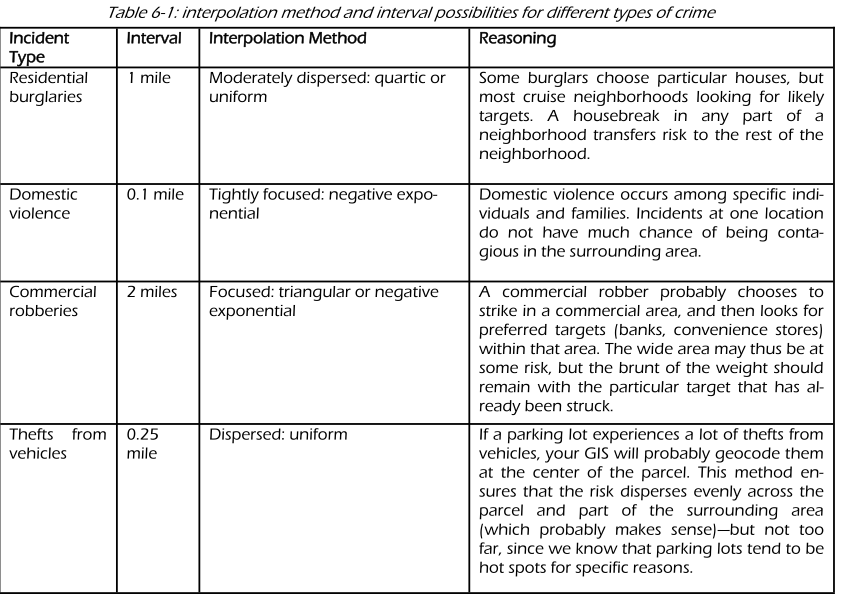 (Source: Smith and Bruce, 2008.)
(Source: Smith and Bruce, 2008.)
The default kernel in density.ppp() is the gaussian. But there are other options. We can use the epanechnikov, quartic or disc. There are also further options for customisation. We can compare these kernels:
par(mfrow=c(2,2))
plot(density.ppp(jitter_bur, sigma = bw.ppl(jitter_bur),edge=T),
main=paste("Gaussian"))
plot(density.ppp(jitter_bur, kernel = "epanechnikov", sigma = bw.ppl(jitter_bur),edge=T),
main=paste("Epanechnikov"))
plot(density.ppp(jitter_bur, kernel = "quartic", sigma = bw.ppl(jitter_bur),edge=T),
main=paste("Quartic"))
plot(density.ppp(jitter_bur, kernel = "disc", sigma = bw.ppl(jitter_bur),edge=T),
main=paste("Disc"))
When reading these maps you need to understand you are only looking at counts of crime in a smooth surface. Nothing more, nothing less. Unlike with choropleth maps we are not normalising the data. We are simply showing the areas where there is more crime, but we are not adjusting for anything (like number of people in the area, or number of houses to burgle). So, it is important you keep this in the back of your mind. As this comic suggests you may end up reading too much into it if you don’t remember this. There are ways to produce density maps adjusting for a second variable, such as population size, but we do not have the time to cover this.
There are also general considerations to keep in mind. Hot spots of crime are a simply a convenient perceptual construct. As Ned Levine (2013: 7.1) highlights “Hot spots do not exist in reality, but are areas where there is sufficient clustering of certain activities (in this case, crime) such that they get labeled such. There is not a border around these incidents, but a gradient where people draw an imaginary line to indicate the location at which the hot spot starts.” Equally, there is not a unique solution to the identification of hot spots. Different techniques and algorithms will give you different answers. As Levine (2013: 7.7) emphasises: “It would be very naive to expect that a single technique can reveal the existence of hot spots in a jurisdiction that are unequivocally clear. In most cases, analysts are not sure why there are hot spots in the first place. Until that is solved, it would be unreasonable to expect a mathematical or statistical routine to solve that problem.” So, as with most data analysis exercises one has to try different approaches and use professional judgement to select a particular representation that may work best for a particular use. Equally, we should not reify what we produce and, instead, take the maps as a starting point for trying to understand the underlying patterns that are being revealed. Critically you want to try several different methods. You will be more persuaded a location is a hot spot if several methods for hot spot analysis point to the same location.
6.3.2 Activity 4: Adding some context
Often it is convenient to use a basemap to provide context. In order to do that we first need to turn the image object generated by the spatstat package into a raster object, a more generic format for raster image used in R. Remember rasters from the first week? Now we finally get to use them a bit!
library(terra)
dmap1 <- density.ppp(jitter_bur, sigma = bw.ppl(jitter_bur),edge=T)
r1 <- rast(dmap1)
#remove very low density values
r1[r1 < 0.0001 ] <- NA
class(r1)## [1] "SpatRaster"
## attr(,"package")
## [1] "terra"Now that we have the raster we can add it to a basemap.
Two-dimensional SpatRaster objects (from the terra package) can be turned into images and added to Leaflet maps using the addRasterImage() function.
The addRasterImage() function works by projecting the SpatRaster object to EPSG:3857 and encoding each cell to an RGBA color, to produce a PNG image. That image is then embedded in the map widget.
It’s important that the SpatRaster object is tagged with a proper coordinate reference system. Many raster files contain this information, but some do not. Here is how you’d tag a raster layer object “r1” which contains WGS84 data:
library(leaflet)
#make sure we have right CRS, which in this case is British National Grid
epsg27700 <- "+proj=tmerc +lat_0=49 +lon_0=-2 +k=0.9996012717 +x_0=400000 +y_0=-100000 +ellps=airy +towgs84=446.448,-125.157,542.06,0.15,0.247,0.842,-20.489 +units=m +no_defs"
crs(r1) <- epsg27700
#we also create a colour palet
pal <- colorNumeric(c("#0C2C84", "#41B6C4", "#FFFFCC"), values(r1),
na.color = "transparent")
#and then make map!
leaflet() %>%
addTiles() %>%
addRasterImage(r1, colors = pal, opacity = 0.8) %>%
addLegend(pal = pal, values = values(r1),
title = "Burglary map")And there you have it. Perhaps those familiar with Fallowfield have some guesses as to what may be going on there?
6.4 Spatial point patterns along networks
Have a look at these maps. Can we say that the spatial point process is random here? Can you identify the areas where we have hotspots of crime? Think about these questions for a little while.
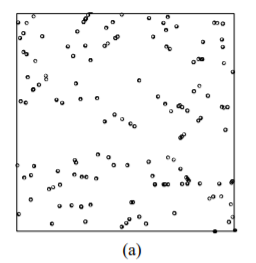 (Source: Okabe and Sugihara, 2012)
(Source: Okabe and Sugihara, 2012)
Ok, so most likely you concluded that the process wasn’t random, which it isn’t in truth. It is also likely that you identified a number of potential hotspots?
Now, look at the two maps below:
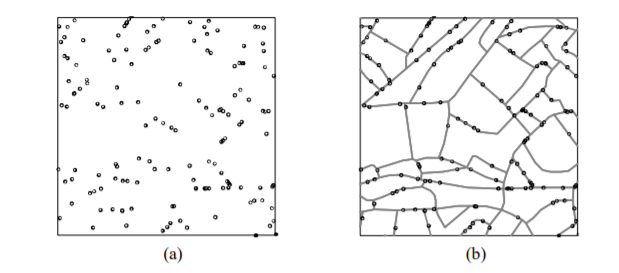 (Source: Okabe and Sugihara, 2012)
(Source: Okabe and Sugihara, 2012)
We are representing the same spatial point pattern process in each of them. But we do have additional information in map B. We now know the street layout. The structure we observed in the map is accounted by the street layout. So what look like a non random spatial point process when we considered the full two dimensional space, now looks less random when we realise that the points can only appear alongside the linear network.
This problem is common in criminal justice applications. Crime is geocoded alongside a linear street network. Even if in physical space crime can take place along a spatial continuum, once crime is geocoded it will only be possible alongside the street network used for the geocoding process.
6.4.1 Activity 5: Spatial point pattern processes along networks
For exploring this kind of spatial point pattern processes along networks we need special techniques. Some researchers have developed special applications, such as SANET. The spatstat package also provides some functionality for this kind of data structures.
In spatstat a point pattern on a linear network is represented by an object of class lpp. The functions lpp() and as.lpp() convert raw data into an object of class lpp (but they require a specification of the underlying network of lines, which is represented by an object of class linnet). For simplicity and illustration purposes we will use the chicago dataset that is distributed as part of the spatstat package. The chicago data is of class lpp and contains information on crime in an area of Chicago.
## Multitype point pattern on linear network
## 116 points
## Linear network with 338 vertices and 503 lines
## Total length 31150.21 feet
## Average intensity 0.003723891 points per foot
## Types of points:
## frequency proportion intensity
## assault 21 0.18103450 0.0006741528
## burglary 5 0.04310345 0.0001605126
## cartheft 7 0.06034483 0.0002247176
## damage 35 0.30172410 0.0011235880
## robbery 4 0.03448276 0.0001284100
## theft 38 0.32758620 0.0012198950
## trespass 6 0.05172414 0.0001926151
## Enclosing window: rectangle = [0.3894, 1281.9863] x [153.1035, 1276.5602] feetAn lpp object contains the linear network information, the spatial coordinates of the data points, and any number of columns of marks (in this case the mark is telling us the type of crime we are dealing with). It also contains the local coordinates seg and tp for the data points. The local coordinate seg is an integer identifying the particular street segment the data point is located in. A segment is each of the sections of a street between two vertices (marking the intersection with another segment). The local coordinate tp is a real number between 0 and 1 indicating the position of the point within the segement: tp=0 corresponds to the first endpoint and tp=1 correspond to the second endpoint.
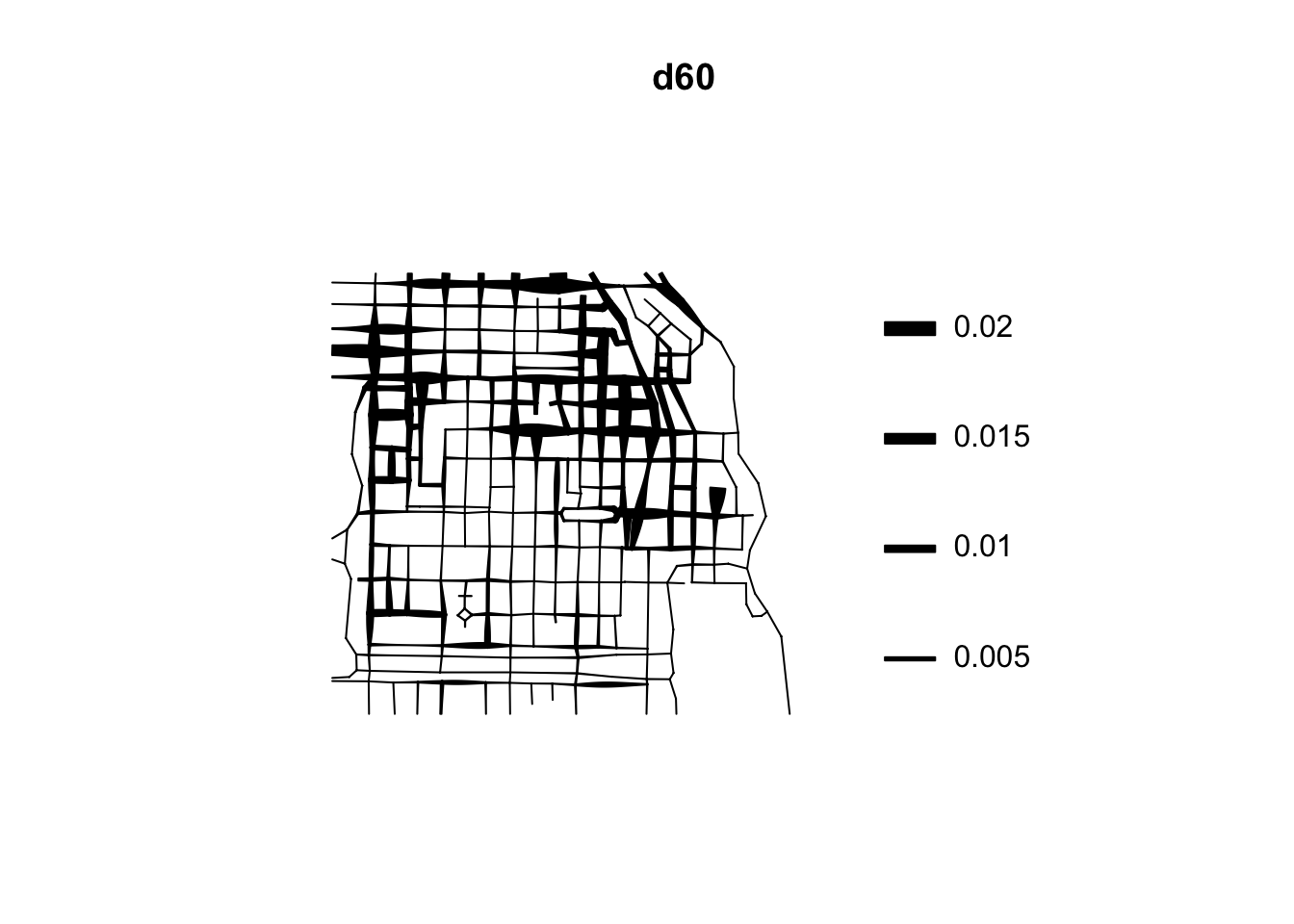
The visual inspection of the map suggest that the intensity of crime along the network is not spatially uniform. Crime seems to be concentrated in particular segments. Like we did before we can estimate the density of data points along the networks using Kernel estimation (with the density.lpp() function), only now we only look at the street segments (rather than areas of the space that are outside the segments). The authors of the package are planning to introduce methods for automatic bandwidth selection but for now this is not possible, so we have to select a bandwidth. We could for example select 60 feet.
We use unmark() to ignore the fact the data points are marked (that is they provide marks with informtation, in this case about the crime type). By using unmark() in this example we will run density estimation for all crimes (rather than by type of crime). We can see the results below:
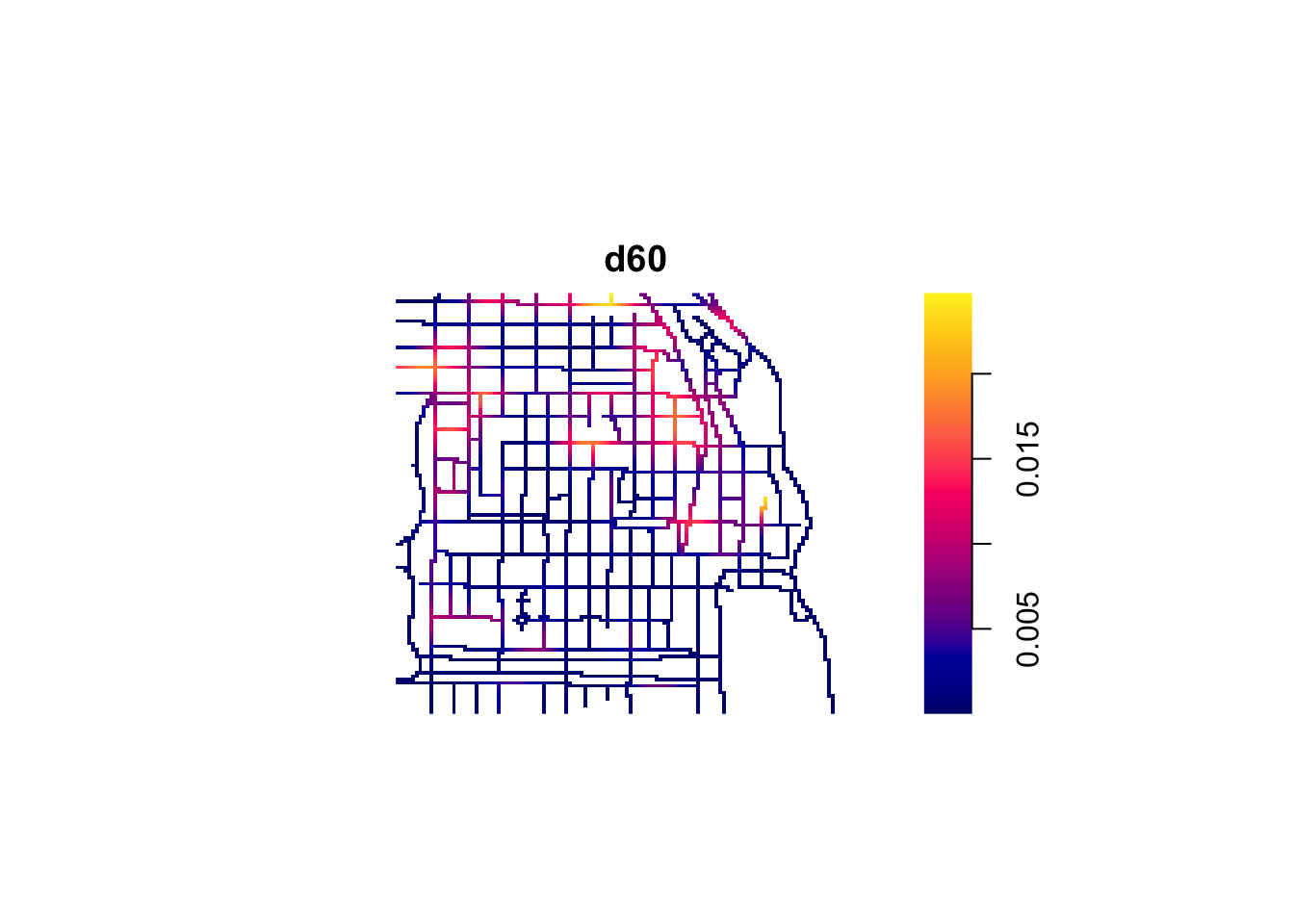
If rather than colour you want to use the thickness of the street segment to identify hotpspots you would need to modify the code as shown below:
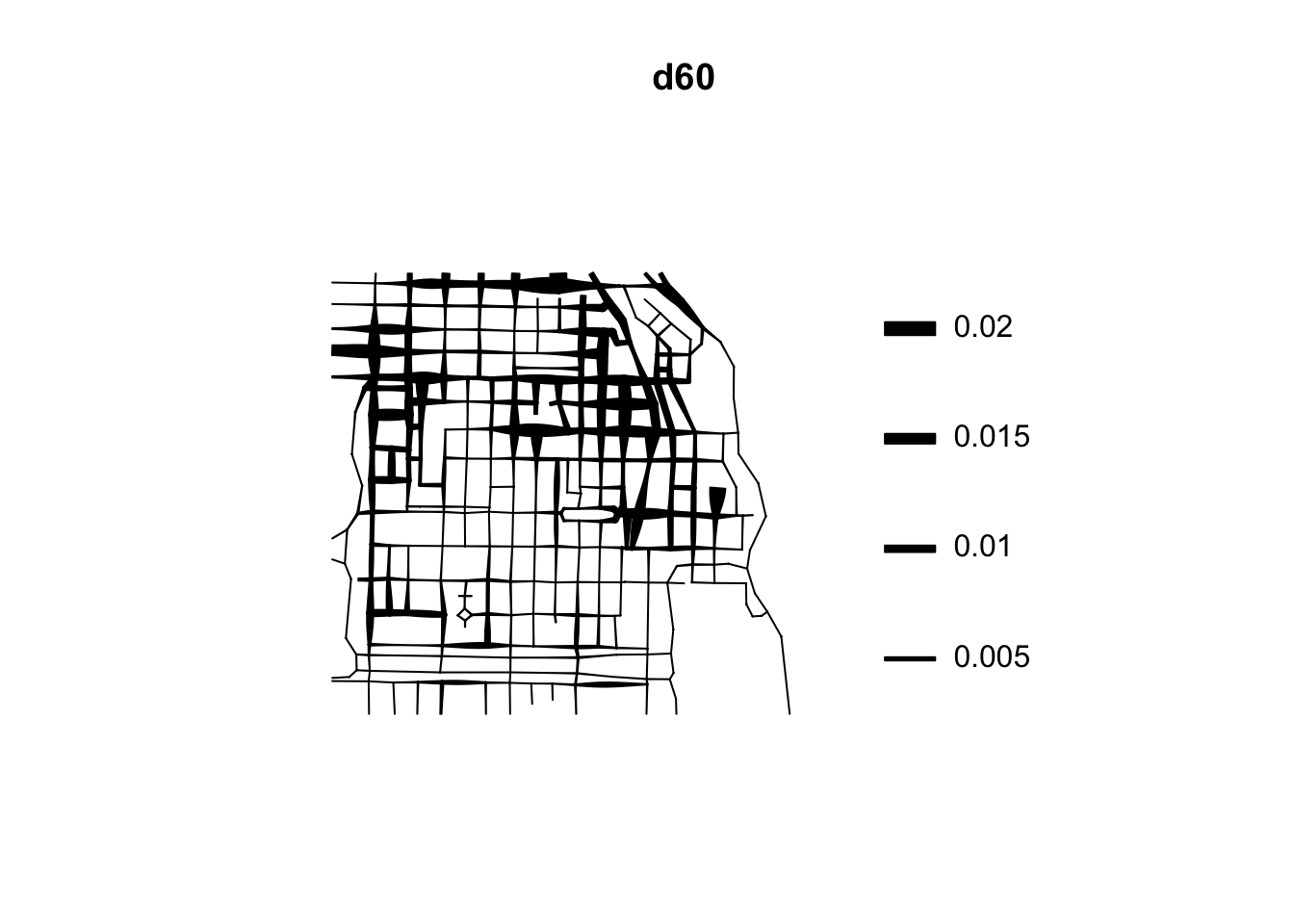
This is very important for crime research, as offending will be constrained by all sorts of networks. Traditionally, hotspot analysis has been directed at crimes that are assumed to be situated across an infinite homogeneous environment (e.g., theft of motor vehicle), we must develop an increased awareness of perceptible geographical restrictions. There has been increasing recognition in recent years that the spatial existence of many phenomena is constrained by networks.
These networks may be roads or rail networks, but there may be many more:
Environmental crimes could exist along waterways such as streams, canals, and rivers; and thefts of metal could occur along utility networks such as pipelines. Those sociologically inclined might be able to offer more examples in the way of interpersonal networks.
While sometimes there may be issues with linking points to routes due to problems such as bad geocoding, as we had discusses in great detail in week 4, there are obvious advantages to considering crime as distributed along networks, rather than continuous space.
Now we have some ways of identifying hot spots under our belts!
6.5 Summary
Today we learned about spatial point patterns. Specifically we explored how to do the following: - we looked at dividing our polygon into quadrants, and counting the number of crimes in each one - we used kernel density estimation to look for concentration of crimes in euclidean space - saved our kernel density heat map as a raster layer and presented on an interactive map - looked at spatial clustering along networks